之前做运维,有一些印象很深的事故,今天来讲其中一个,为了大家能理解,先说一些背景。现在因为流量巨大,单台机器肯定不足以为所有用户提供服务,所以大公司几乎任何一个服务的背后都是一套集群,然而任意一台机器不是100%可靠,如果你想让你服务尽可能接近100%可靠,你的集群就得具备检测和剔除坏点的能力。
之前在阿里广泛使用的是LVS负载均衡,LVS集群就支持坏点检测和剔除,用户访问大概架构如下。
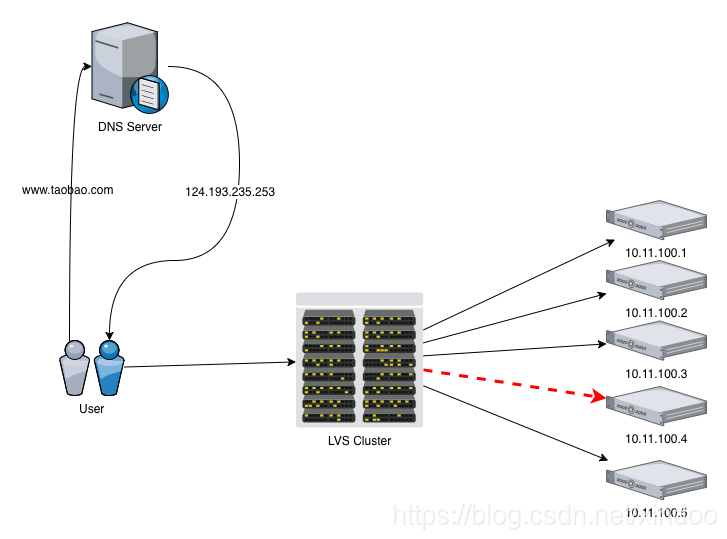
起始网络请求经过的路径远比这个复杂,我这里只是个示意图。lvs集群必须能检测到10.11.100.4这台机器的异常。你说啥?lvs是做啥的?我们在访问淘宝的时候,拿到的ip地址并不是真正提供服务的服务器ip地址,不行你用dig命令看下。就两台服务器给几亿用户用?不可能的!!
你看到的两个IP只是负载均衡lvs集群的ip,lvs会把你的请求转发的真正提供服务的机器上去。通过lvs转发有好多优点。
1. 节省公网ip,像淘宝这么大的网站,如果服务器全部挂域名下面,这就得需要成千上万公网ip,如果每个公司都这么做,ipv4资源早就耗尽了。
2. 更高的可用性,dns是用缓存的,几分钟到十几分钟不等,如果有ip变化,可能意味着大批用户在十几分钟内都拿到的是错误的ip。但lvs下面的ip可用很快切换。
3. 更方便的运维。如果流量变化,可用快速在lvs下增删机器,出现坏点,lvs也可以快速把坏的机器流量切走。
今天要说的这个事故,就和lvs第三个优点有关,就是有个vip下有一批机器服务有问题,但其实lvs机器并没有将其下线。这里并不是说lvs本身出现了问题,根本原因其实是运维在配置lvs Health Check方式不合理导致的。
阿里lvs集群其实提供了两种对web服务Health Check的方式。1.检测服务端口是否打开,只要服务器端口支持开着就认为是正常。 2.发出一个http请求,看状态码是否正常。
事故那次都是用的第一种health check方式,问题的本质在于,端口开着服务并不一定正常,所以lvs把大量请求转发到这些端口开着但服务异常的机器上,这些请求便得不到正常的响应。 第一种health check起始只是在OSI网络分层的第4层传输层做检测,它起始只能检测数据能否被正常的传送到。 而第二种health check方式是在第7层应用层做的,它不仅能保证数据能否被传送到,而且还检测能否被正常处理。

那是不是全部切换到第7层就是最好的解决方案呢,虽然我们当时也是这么做的,为了防止类似的事故发生,我们对阿里妈妈所有的vip都做了检查,全部切换到第二种检查方式。 但其实我觉得这也并不一定是最好的方式,本身对lvs集群而言,4层检查比7层要省事多了,而且对自生的负载压力也小。 另一个原因是,这种应用异常的问题应该交由监控系统去检测,而不是让一个和业务毫无关联的基础服务区兜底。其实当时我们也做了监控上的完善。