前两天逛博客的时候看到有个人写了一篇博客说ReentrantLock比synchronized慢,这就很违反我的认知了,详细看了他的博客和测试代码,发现了他测试的不严谨,并在评论中友好地指出了他的问题,结果他直接把博客给删了 删了 了……
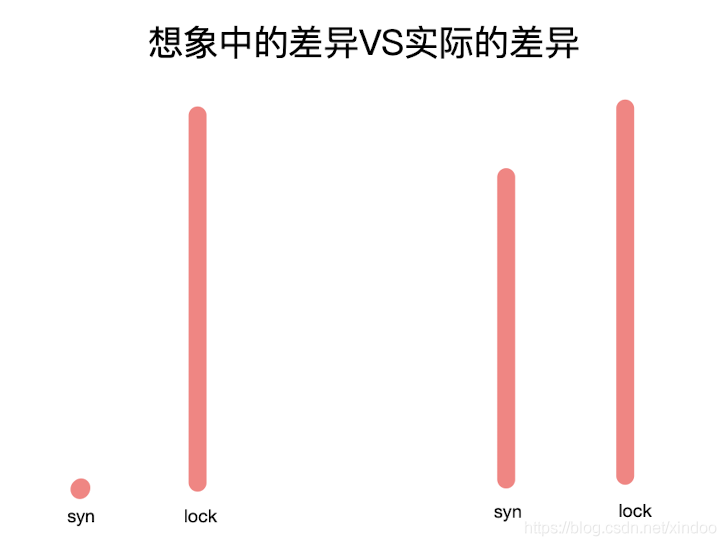
很多老一辈的程序猿对有synchronized有个 性能差 的刻板印象,然后极力推崇使用java.util.concurrent包中的lock类,如果你追问他们synchronized和lock实现性能差多少,估计没几个人能答出来。 说到这你是不是也很想知道我的测试结果? synchronized与ReentrantLock所实现的功能差不多,用途也大幅度重合,索性我们就来测测这二者的性能差异。
实测结果
测试平台:jdk11, MacBook Pro (13-inch, 2017) , jmh测试
测试代码如下:
public class LockTest {
private static Object lock = new Object();
private static ReentrantLock reentrantLock = new ReentrantLock();
private static long cnt = 0;
@Benchmark
@Measurement(iterations = 2)
@Threads(10)
@Fork(0)
@Warmup(iterations = 5, time = 10)
public void testWithoutLock(){
doSomething();
}
@Benchmark
@Measurement(iterations = 2)
@Threads(10)
@Fork(0)
@Warmup(iterations = 5, time = 10)
public void testReentrantLock(){
reentrantLock.lock();
doSomething();
reentrantLock.unlock();
}
@Benchmark
@Measurement(iterations = 2)
@Threads(10)
@Fork(0)
@Warmup(iterations = 5, time = 10)
public void testSynchronized(){
synchronized (lock) {
doSomething();
}
}
private void doSomething() {
cnt += 1;
if (cnt >= (Long.MAX_VALUE >> 1)) {
cnt = 0;
}
}
public static void main(String[] args) {
Options options = new OptionsBuilder().include(LockTest.class.getSimpleName()).build();
try {
new Runner(options).run();
} catch (Exception e) {
} finally {
}
}}
Benchmark Mode Cnt Score Error Units
LockTest.testReentrantLock thrpt 2 32283819.289 ops/s
LockTest.testSynchronized thrpt 2 25325244.320 ops/s
LockTest.testWithoutLock thrpt 2 641215542.492 ops/s没错synchronized性能确实更差,但就只差20%左右,第一次测试的时候我也挺诧异的,知道synchronized会差,但那种预期中几个数量级的差异却没有出现。 于是我又把@Threads线程数调大了,增加了多线程之间竞争的可能性,得到了如下的结果。
Benchmark Mode Cnt Score Error Units
LockTest.testReentrantLock thrpt 2 29464798.051 ops/s
LockTest.testSynchronized thrpt 2 22346035.066 ops/s
LockTest.testWithoutLock thrpt 2 383047064.795 ops/s性能差异稍有拉开,但还是在同一量级上。
结论
无可置疑,synchronized的性能确实要比ReentrantLock差个20%-30%,那是不是代码中所有用到synchronized的地方都应该换成lock? 非也,仔细想想看,ReentrantLock几乎和可以替代任何使用synchronized的场景,而且性能更好,那为什么jdk一直要留着这个关键词呢?而且完全没有任何想要废弃它的想法。
黑格尔说过存在即合理, synchronized因多线程应运而生,它的存在也大幅度简化了Java多线程的开发。没错,它的优势就是使用简单,你不需要显示去加减锁,相比之下ReentrantLock的使用就繁琐的多了,你加完锁之后还得考虑到各种情况下的锁释放,稍不留神就一个bug埋下了。

但ReentrantLock的繁琐之下,它也提供了更复杂的api,足以应对更多更复杂的需求,详细可以参考我之前的博客ReentrantLock源码解析。
如今synchronized与ReentrantLock二者的性能差异不再是选谁的主要因素,你在做选择的时候更应该考虑的是其易用性、功能性和代码的可维护性…… 二者30%的性能差异决定不了什么,如果你真想优化代码的性能,你应该选择的是其他的切入点,而不是斤斤计较这个,切记不要拣了芝麻丢了西瓜。
文章本该到这里就结束了,但我仍然好奇为什么synchronized给老一辈java程序猿留下了性能差的印象,无奈jdk1.5及之前的资料已经比较久远 不太好找,但是jdk1.6对synchronized的性能提升做了啥还是很好找的。
jdk对synchronized优化了啥?
如果你对代码段加了synchronized的,jvm编译后就会在其前后分别插入monitorenter和monitorexit指令,如下:
void onlyMe(Foo f) {
synchronized(f) {
doSomething();
}
}编译后:
Method void onlyMe(Foo)
0 aload_1 // Push f
1 dup // Duplicate it on the stack
2 astore_2 // Store duplicate in local variable 2
3 monitorenter // Enter the monitor associated with f
4 aload_0 // Holding the monitor, pass this and...
5 invokevirtual #5 // ...call Example.doSomething()V
8 aload_2 // Push local variable 2 (f)
9 monitorexit // Exit the monitor associated with f
10 goto 18 // Complete the method normally
13 astore_3 // In case of any throw, end up here
14 aload_2 // Push local variable 2 (f)
15 monitorexit // Be sure to exit the monitor!
16 aload_3 // Push thrown value...
17 athrow // ...and rethrow value to the invoker
18 return // Return in the normal case
Exception table:
From To Target Type
4 10 13 any
13 16 13 any加锁和释放锁的性能消耗其实就体现在了 monitorenter和monitorexit两个指令上了,如果是优化性能,肯定也是在这两个指令上优化了。 查阅《Java并发编程的艺术》发现,Java6为了减少锁获取和释放带来的性能消耗,引入了锁分级的策略。 将锁状态分别分成 无锁、偏向锁、轻量级锁、重量级锁 四个状态,其性能依次递减。但所幸因为局部性的存在,大多数并发情况下偏向锁或者轻量级锁就能满足我们的需求,而且锁只有在竞争严重的情况下才会升级,所以大多数情况下synchronized性能也不会太差。
由此,我们可以大致反推出在jdk1.6之前,锁是不分级的,只有重量级锁,线程只要没获取到锁就阻塞,从而导致其性能低下。
最后我在jdk11u的源码里找到了monitorenter和monitorexit的x86版本的实现(汇编指令和具体平台相关)献给大家,欢迎有志之士研读下。
//-----------------------------------------------------------------------------
// Synchronization
//
// Note: monitorenter & exit are symmetric routines; which is reflected
// in the assembly code structure as well
//
// Stack layout:
//
// [expressions ] <--- rsp = expression stack top
// ..
// [expressions ]
// [monitor entry] <--- monitor block top = expression stack bot
// ..
// [monitor entry]
// [frame data ] <--- monitor block bot
// ...
// [saved rbp ] <--- rbp
void TemplateTable::monitorenter() {
transition(atos, vtos);
// check for NULL object
__ null_check(rax);
const Address monitor_block_top(
rbp, frame::interpreter_frame_monitor_block_top_offset * wordSize);
const Address monitor_block_bot(
rbp, frame::interpreter_frame_initial_sp_offset * wordSize);
const int entry_size = frame::interpreter_frame_monitor_size() * wordSize;
Label allocated;
Register rtop = LP64_ONLY(c_rarg3) NOT_LP64(rcx);
Register rbot = LP64_ONLY(c_rarg2) NOT_LP64(rbx);
Register rmon = LP64_ONLY(c_rarg1) NOT_LP64(rdx);
// initialize entry pointer
__ xorl(rmon, rmon); // points to free slot or NULL
// find a free slot in the monitor block (result in rmon)
{
Label entry, loop, exit;
__ movptr(rtop, monitor_block_top); // points to current entry,
// starting with top-most entry
__ lea(rbot, monitor_block_bot); // points to word before bottom
// of monitor block
__ jmpb(entry);
__ bind(loop);
// check if current entry is used
__ cmpptr(Address(rtop, BasicObjectLock::obj_offset_in_bytes()), (int32_t) NULL_WORD);
// if not used then remember entry in rmon
__ cmovptr(Assembler::equal, rmon, rtop); // cmov => cmovptr
// check if current entry is for same object
__ cmpptr(rax, Address(rtop, BasicObjectLock::obj_offset_in_bytes()));
// if same object then stop searching
__ jccb(Assembler::equal, exit);
// otherwise advance to next entry
__ addptr(rtop, entry_size);
__ bind(entry);
// check if bottom reached
__ cmpptr(rtop, rbot);
// if not at bottom then check this entry
__ jcc(Assembler::notEqual, loop);
__ bind(exit);
}
__ testptr(rmon, rmon); // check if a slot has been found
__ jcc(Assembler::notZero, allocated); // if found, continue with that one
// allocate one if there's no free slot
{
Label entry, loop;
// 1. compute new pointers // rsp: old expression stack top
__ movptr(rmon, monitor_block_bot); // rmon: old expression stack bottom
__ subptr(rsp, entry_size); // move expression stack top
__ subptr(rmon, entry_size); // move expression stack bottom
__ mov(rtop, rsp); // set start value for copy loop
__ movptr(monitor_block_bot, rmon); // set new monitor block bottom
__ jmp(entry);
// 2. move expression stack contents
__ bind(loop);
__ movptr(rbot, Address(rtop, entry_size)); // load expression stack
// word from old location
__ movptr(Address(rtop, 0), rbot); // and store it at new location
__ addptr(rtop, wordSize); // advance to next word
__ bind(entry);
__ cmpptr(rtop, rmon); // check if bottom reached
__ jcc(Assembler::notEqual, loop); // if not at bottom then
// copy next word
}
// call run-time routine
// rmon: points to monitor entry
__ bind(allocated);
// Increment bcp to point to the next bytecode, so exception
// handling for async. exceptions work correctly.
// The object has already been poped from the stack, so the
// expression stack looks correct.
__ increment(rbcp);
// store object
__ movptr(Address(rmon, BasicObjectLock::obj_offset_in_bytes()), rax);
__ lock_object(rmon);
// check to make sure this monitor doesn't cause stack overflow after locking
__ save_bcp(); // in case of exception
__ generate_stack_overflow_check(0);
// The bcp has already been incremented. Just need to dispatch to
// next instruction.
__ dispatch_next(vtos);
}
void TemplateTable::monitorexit() {
transition(atos, vtos);
// check for NULL object
__ null_check(rax);
const Address monitor_block_top(
rbp, frame::interpreter_frame_monitor_block_top_offset * wordSize);
const Address monitor_block_bot(
rbp, frame::interpreter_frame_initial_sp_offset * wordSize);
const int entry_size = frame::interpreter_frame_monitor_size() * wordSize;
Register rtop = LP64_ONLY(c_rarg1) NOT_LP64(rdx);
Register rbot = LP64_ONLY(c_rarg2) NOT_LP64(rbx);
Label found;
// find matching slot
{
Label entry, loop;
__ movptr(rtop, monitor_block_top); // points to current entry,
// starting with top-most entry
__ lea(rbot, monitor_block_bot); // points to word before bottom
// of monitor block
__ jmpb(entry);
__ bind(loop);
// check if current entry is for same object
__ cmpptr(rax, Address(rtop, BasicObjectLock::obj_offset_in_bytes()));
// if same object then stop searching
__ jcc(Assembler::equal, found);
// otherwise advance to next entry
__ addptr(rtop, entry_size);
__ bind(entry);
// check if bottom reached
__ cmpptr(rtop, rbot);
// if not at bottom then check this entry
__ jcc(Assembler::notEqual, loop);
}参考资料
- Java Virtual Machine Specification 3.14. Synchronization
- 《Java并发编程的艺术》 2.2 synchronized的实现原理和应用