本来打算只用一篇文章来讲解Redis中的list,在实际写作过程中发现Redis中有多种list的实现,所以准备拆成多篇文章,本文主要讲ziplist,ziplist也是quicklist的基础。另外还有skiplist,skiplist虽然是list,当主要和set命令相关,所以会放到后面。
本文主要涉及到的源码在ziplist.c
何为ziplist?我们可以在ziplist.c源码头部找到一段Redis作者的一段介绍。
The ziplist is a specially encoded dually linked list that is designed to be very memory efficient. It stores both strings and integer values, where integers are encoded as actual integers instead of a series of characters. It allows push and pop operations on either side of the list in O(1) time.However, because every operation requires a reallocation of the memory used by the ziplist, the actual complexity is related to the amount of memory used by the ziplist.
ziplist是为了提高存储效率而设计的一种特殊编码的双向链表。它可以存储字符串或者整数,存储整数时是采用整数的二进制而不是字符串形式存储。他能在O(1)的时间复杂度下完成list两端的push和pop操作。但是因为每次操作都需要重新分配ziplist的内存,所以实际复杂度和ziplist的内存使用量相关。
前半句还好理解,但每次操作都需要重新分配内存…… 就有点耐人寻味了。别急,你看完ziplist的具体实现就懂了。
ziplist在逻辑上是个双向链表,但它是存储在一大块连续的内存空间上的。与其说ziplist是个数据结构,倒不如说他是Redis中双向链表的序列化存储方式。
ziplist结构
整个ziplist在内存中的存储格式如下:
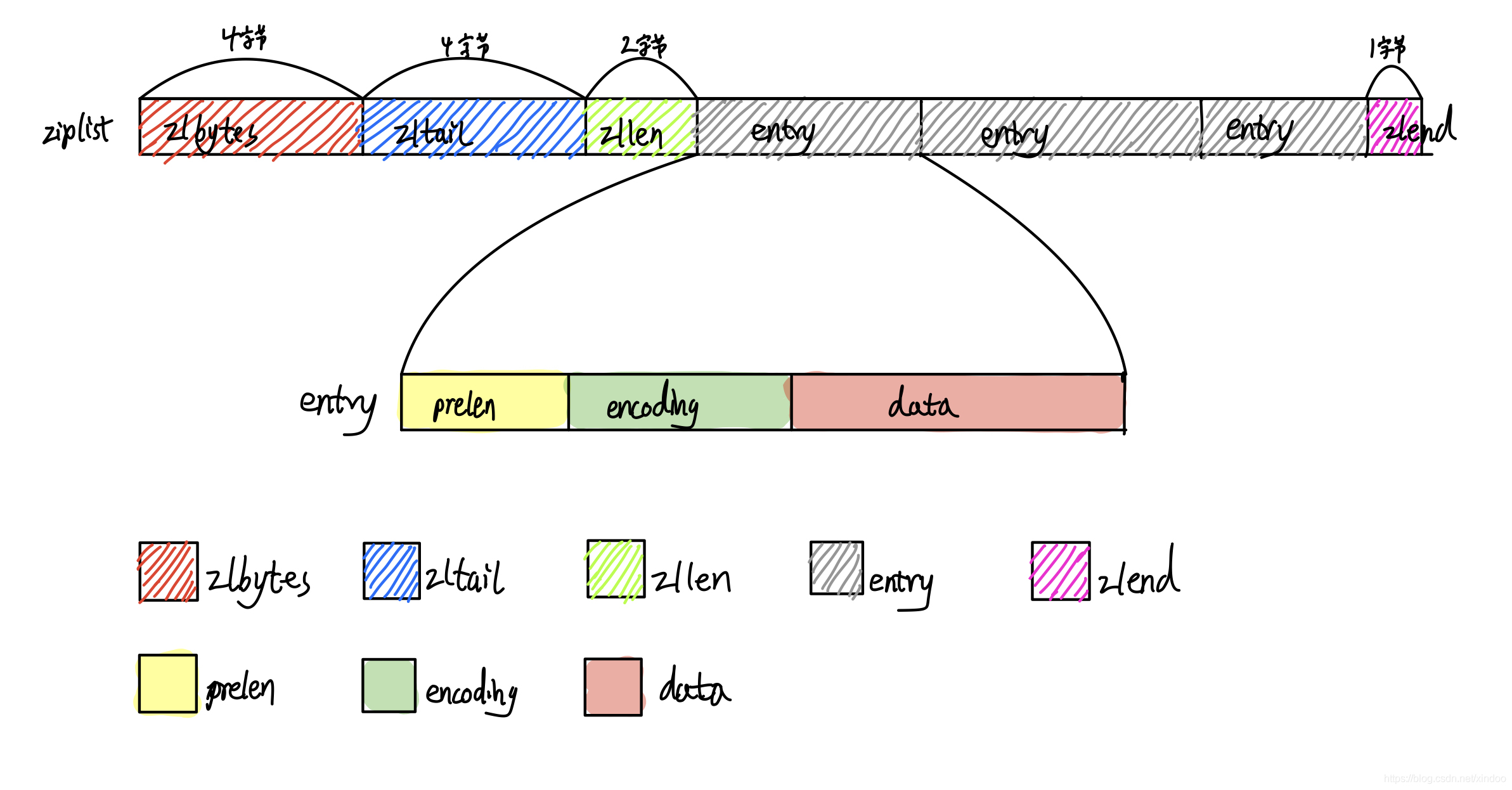
ziplist主要有这么几个部分:
- zlbytes: 32位无符号整型,表示整个ziplist所占的空间大小,包含了zlbytes所占的4个字节。
- 这个字段可以在重置整个ziplist大小时不需要遍历整个list来确定大小,空间换时间。
- zltail: 32位无符号整型,表示整个list中最后一项所在的偏移量,方便在尾部做pop操作。
- zllen: 16位,表示ziplist中所存储的entry数量,但是注意,这里最多表示$2^{16} -2$个entry, 如果是$2^{16}-1$有特殊含义,$2^{16}-1$表示存储数量超过了$2^{16}-2$个,但具体是多少个得遍历一次才能知道。
- zlend: 8位,ziplist的末尾表示,值固定是255.
- entry: 不定长,可能有多个,list中具体的数据项,下面会详细介绍。
entry
这里最核心的就是entry的数据格式,entry还真有些复杂,从上图中可以看出它主要有三个部分。
- prelen: 前一个entry的存储大小,主要是为了方便从后往前遍历。
- encoding: 数据的编码形式(字符串还是数字,长度是多少)
- data: 实际存储的数据
比较复杂的是Redis为了节省内存空间,对上面三个字段设计了一套比较复杂的编码方式,本质上就是一套变长的编码协议,具体规则如下:
prelen
如果prelen数值小于254,那就只用一个字节来表示长度,如果长度大于等于254就用5个字节,第一个字节是固定值254(FE)来标识这是个特殊的数据,剩下的4个字节来表示实际的长度。
encoding
encoding的具体值取决于entry中具体的内容,当entry是个string时,encoding的前两字节存储了字符串的长度。当entry是一个整数的时候,前两字节默认都是1,后面两字节标识出后面存的是哪种类型的整数,第一个字节就足够判断出entry是什么类型了。不同的encoding类型示例如下:
-
|00pppppp| - 1字节
长度小于或者等于63的String类型,'pppppp'无符号6位数标识string长度。
-
|01pppppp|qqqqqqqq| - 2字节
长度小于或者等于16383的String类型(14位),注意:14位'pppppp'采用大端的方式存储
-
|10000000|qqqqqqqq|rrrrrrrr|ssssssss|tttttttt| - 5字节
长度大于等于16384的String类型,第二字节开始的qqrrsstt都是用来存储字符串长度的二进制位,可表示的字符串长度最大2^32-1,第一字节的低6位没有用,所以都是0。
注意: 32位数采用大端的方式存储 -
|11000000| - 3字节
存储int16_t (2字节).
-
|11010000| - 5字节
存储int32_t (4字节).
-
|11100000| - 9字节
存储int64_t (8字节).
-
|11110000| - 4字节
24位有符号类型整数 (3字节).
-
|11111110| - 2字节
8位有符号类型整数 (1字节).
- |1111xxxx| - (xxxx在0001和1101之间) 4位无符号整数.
0到12的无符号整数.编码值实际上是从1到13,因为0000和1111不能使用,要留出一位表示0,所以应该从编码值中减去1才是准确值
- |1111xxxx| - (xxxx在0001和1101之间) 4位无符号整数.
在某些比较小的数值下,具体值可以直接存储到encoding字段里。
ziplist的API
ziplist.c代码也较多,双链表操作很多代码在ziplist中比较多,其实本质上都是它这复杂的存储格式导致的,实际上理解了它的编码格式,具体代码不难理解。这里我只列出几个我认为比较重要的API,其他可以参考源码ziplist.c。
ziplist其实只是一种双向队列的序列化方式,是在内存中的存储格式,实际上并不能直接拿过来用,用户看到的ziplist只是一个char *指针,其中每个entry在实际使用中还需要反序列化成zlentry方便调用。
typedef struct zlentry {
unsigned int prevrawlensize; /* 内存中编码后的prevrawlen用了多少字节 */
unsigned int prevrawlen; /* 前一个entry占用的长度,主要是为了entry之间跳转 */
unsigned int lensize; /* 内存中编码后的len用了多少字节 */
unsigned int len; /* 当前entry的长度,如果是string则表示string的长度,如果是整数,则len依赖于具体数值大小。*/
unsigned int headersize; /* prevrawlensize + lensize. entry的head部分用了多少字节 */
unsigned char encoding; /* 当前entry的编码格式 */
unsigned char *p; /* 指向数据域的指针 */
} zlentry;另外有一点,ziplist在内存中是高度紧凑的连续存储,这意味着它起始对修改并不友好,如果要对ziplist做修改类的操作,那就需重新分配新的内存来存储新的ziplist,代价很大,具体插入和删除的代码如下。
/* 在p位置插入数据 *s. */
unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen;
unsigned int prevlensize, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789; /* initialized to avoid warning. Using a value
that is easy to see if for some reason
we use it uninitialized. */
zlentry tail;
/* 找到前一个节点计算出prevlensize和prevlen */
if (p[0] != ZIP_END) {
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
} else {
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
prevlen = zipRawEntryLength(ptail);
}
}
/* See if the entry can be encoded */
if (zipTryEncoding(s,slen,&value,&encoding)) {
/* 'encoding' is set to the appropriate integer encoding */
reqlen = zipIntSize(encoding);
} else {
/* 'encoding' is untouched, however zipStoreEntryEncoding will use the
* string length to figure out how to encode it. */
reqlen = slen;
}
/* We need space for both the length of the previous entry and
* the length of the payload. */
reqlen += zipStorePrevEntryLength(NULL,prevlen);
reqlen += zipStoreEntryEncoding(NULL,encoding,slen);
/* When the insert position is not equal to the tail, we need to
* make sure that the next entry can hold this entry's length in
* its prevlen field. */
int forcelarge = 0;
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
if (nextdiff == -4 && reqlen < 4) {
nextdiff = 0;
forcelarge = 1;
}
/* Store offset because a realloc may change the address of zl. */
offset = p-zl;
// 计算出需要的内存容量,然后重新生成一个新大小的zl替换掉原来的zl。
zl = ziplistResize(zl,curlen+reqlen+nextdiff);
p = zl+offset;
/* 迁移数据,然后更新tail的offset */
if (p[0] != ZIP_END) {
/* Subtract one because of the ZIP_END bytes */
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
/* Encode this entry's raw length in the next entry. */
if (forcelarge)
zipStorePrevEntryLengthLarge(p+reqlen,reqlen);
else
zipStorePrevEntryLength(p+reqlen,reqlen);
/* Update offset for tail */
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
/* When the tail contains more than one entry, we need to take
* "nextdiff" in account as well. Otherwise, a change in the
* size of prevlen doesn't have an effect on the *tail* offset. */
zipEntry(p+reqlen, &tail);
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
/* This element will be the new tail. */
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
/* When nextdiff != 0, the raw length of the next entry has changed, so
* we need to cascade the update throughout the ziplist */
if (nextdiff != 0) {
offset = p-zl;
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
/* 写入数据 */
p += zipStorePrevEntryLength(p,prevlen);
p += zipStoreEntryEncoding(p,encoding,slen);
if (ZIP_IS_STR(encoding)) {
memcpy(p,s,slen);
} else {
zipSaveInteger(p,value,encoding);
}
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
}ziplist节点删除
unsigned char *__ziplistDelete(unsigned char *zl, unsigned char *p, unsigned int num) {
unsigned int i, totlen, deleted = 0;
size_t offset;
int nextdiff = 0;
zlentry first, tail;
zipEntry(p, &first);
for (i = 0; p[0] != ZIP_END && i < num; i++) {
p += zipRawEntryLength(p);
deleted++;
}
totlen = p-first.p; /* 删除元素后减少的内存空间(字节) */
if (totlen > 0) {
if (p[0] != ZIP_END) {
/* Storing `prevrawlen` in this entry may increase or decrease the
* number of bytes required compare to the current `prevrawlen`.
* There always is room to store this, because it was previously
* stored by an entry that is now being deleted. */
nextdiff = zipPrevLenByteDiff(p,first.prevrawlen);
/* Note that there is always space when p jumps backward: if
* the new previous entry is large, one of the deleted elements
* had a 5 bytes prevlen header, so there is for sure at least
* 5 bytes free and we need just 4. */
p -= nextdiff;
zipStorePrevEntryLength(p,first.prevrawlen);
/* Update offset for tail */
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))-totlen);
/* When the tail contains more than one entry, we need to take
* "nextdiff" in account as well. Otherwise, a change in the
* size of prevlen doesn't have an effect on the *tail* offset. */
zipEntry(p, &tail);
if (p[tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
/* 把tail移动到ziplist的前面*/
memmove(first.p,p,
intrev32ifbe(ZIPLIST_BYTES(zl))-(p-zl)-1);
} else {
/* The entire tail was deleted. No need to move memory. */
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe((first.p-zl)-first.prevrawlen);
}
/* 更新ziplist大小 */
offset = first.p-zl;
zl = ziplistResize(zl, intrev32ifbe(ZIPLIST_BYTES(zl))-totlen+nextdiff);
ZIPLIST_INCR_LENGTH(zl,-deleted); // 更新zllen
p = zl+offset;
/* When nextdiff != 0, the raw length of the next entry has changed, so
* we need to cascade the update throughout the ziplist */
if (nextdiff != 0)
zl = __ziplistCascadeUpdate(zl,p);
}
return zl;
}插入删除的基本逻辑都是类似,先定位,然后算插入/删除后所需的内存空间变化,根据计算出来新的空间大小对zl做ziplistResize(),然后更新zl的元信息。
除了插入删除外,像ziplistPush ziplistMerge,这这种带改动的API,最后都调用了 ziplistResize, ziplistResize代码如下:
unsigned char *ziplistResize(unsigned char *zl, unsigned int len) {
zl = zrealloc(zl,len);
ZIPLIST_BYTES(zl) = intrev32ifbe(len);
zl[len-1] = ZIP_END;
return zl;
}看起来很简短,其实大量的逻辑都在zrealloc中,zrealloc是个宏定义(突然感觉c的宏定义很骚),其实主要逻辑就是申请一块长度为len的空间,然后释放原来zl所指向的空间。这里可以看出 ziplist修改的代价是很高的 ,如果在使用中有频繁更新list的操作,建议对list相关的配置做些优化。
其他API
具体API定义列表见源码ziplist.h
unsigned char *ziplistNew(void); // 新建ziplist
unsigned char *ziplistMerge(unsigned char **first, unsigned char **second); // 合并两个ziplist
unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where); // 在ziplist头部或者尾部push一个节点
unsigned char *ziplistIndex(unsigned char *zl, int index); // 找到某个下标的节点
unsigned char *ziplistNext(unsigned char *zl, unsigned char *p); // 找到p节点的下一个节点
unsigned char *ziplistPrev(unsigned char *zl, unsigned char *p); // 找到p节点的前一个节点
unsigned int ziplistGet(unsigned char *p, unsigned char **sval, unsigned int *slen, long long *lval); // 获取entry中存储的具体内容
unsigned char *ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen); // 插入
unsigned char *ziplistDelete(unsigned char *zl, unsigned char **p); // 删除
unsigned char *ziplistDeleteRange(unsigned char *zl, int index, unsigned int num); // 删除某个下标区间内的节点
unsigned int ziplistCompare(unsigned char *p, unsigned char *s, unsigned int slen); // 比较两个节点的大小
unsigned char *ziplistFind(unsigned char *p, unsigned char *vstr, unsigned int vlen, unsigned int skip); // 找到某个特定值的节点
unsigned int ziplistLen(unsigned char *zl); // ziplist的长度
size_t ziplistBlobLen(unsigned char *zl); // ziplist的存储空间大小
void ziplistRepr(unsigned char *zl); // 结语
ziplist其实是一个逻辑上的双向链表,可以快速找到头节点和尾节点,然后每个节点(entry)中也包含指向前/后节点的"指针",但作者为了将内存节省到极致,摒弃了传统的链表设计(前后指针需要16字节的空间,而且会导致内存碎片化严重),设计出了内存非常紧凑的存储格式。内存是省下来了,但操作复杂性也更新的复杂度上来了,当然Redis作者也考虑了这点,所以也设计出了ziplist和传统双向链表的折中——quicklist,我们将在下一篇博文中详细介绍quicklist。
本文是Redis源码剖析系列博文,同时也有与之对应的Redis中文注释版,有想深入学习Redis的同学,欢迎star和关注。
Redis中文注解版仓库:https://github.com/xindoo/Redis
Redis源码剖析专栏:https://zxs.io/s/1h