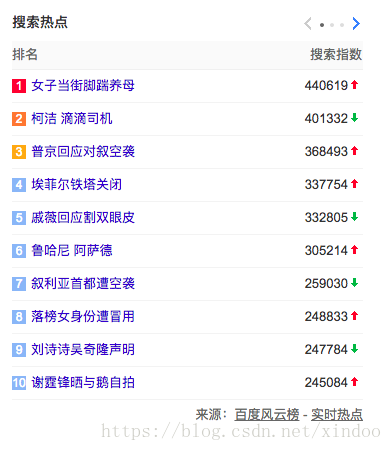
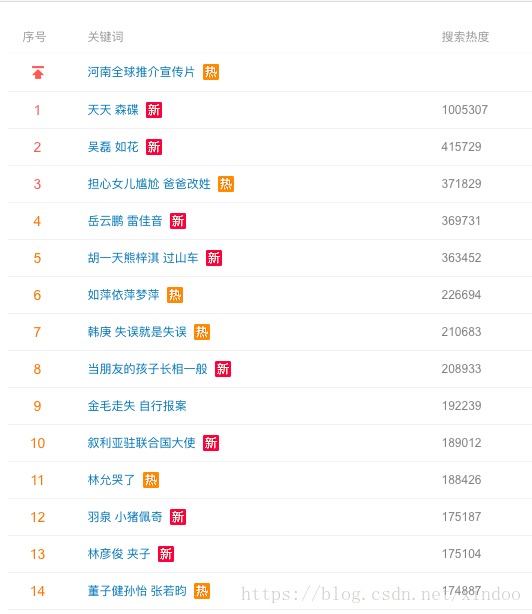
我司内部有个基于jstorm的实时流编程框架,文档里有提到实时Topn,但是还没有实现。。。。这是一个挺常见挺重要的功能,但仔细想想实现起来确实有难度。实时流的TopN其实离大家很近,比如下图百度和微博的实时热搜榜,还有各种资讯类的实时热点,他们具体实现方式不清楚,甚至有可能是半小时离线跑出来的。今天不管他们怎么实现的,我们讨论下实时该怎么实现(基于storm)。
加入我们现在有一些微博搜索记录,求某个时间窗口(以5分钟为例)Topn其实就是对微博搜索记录做word count,然后排序截取前N个。离线情况下可以这么简单的解决了,但在实时流数据下,你每个时刻都会有新数据流进来,当前时刻你拿到数据里的topn在下一时刻就不一定对了。
一个时间窗口的TopN结果必须是建立在该时间窗口的全量数据上的才能保证100%的正确性,然而在实时流情况下,由于各种不确定性的因素,你很难在一个时间窗口内拿到上个时间窗口的数据。以5分钟窗口为例,你想这个5分钟内就求出上个5分钟的热点Topn,但是很可能正常情况下5分钟只能拿到99%的数据,10分钟拿到99.9%的数据,甚至30分钟才能几乎拿到100%的数据。如果数据来源异常,很可能几个小时你都不大可能拿到某个5分钟窗口内的全部数据。百度热搜和微博热搜都没有说这些结果是哪个时间段的,就是想给自己留条后路,万一内部出故障了,好几个小时数据不更新,用户也看不出,哈哈。
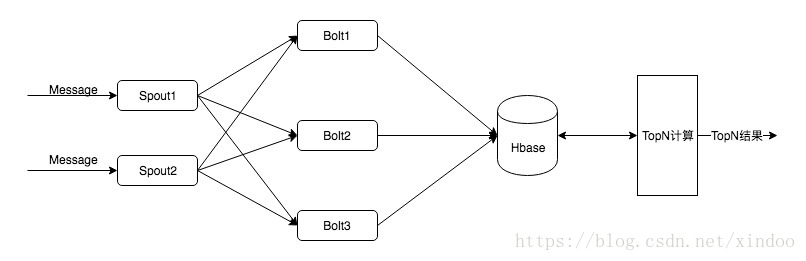
在现实情况下,这个5分钟的热点数据可能下个5分钟就得展示给用户,当然异常情况除外,那我们就可以退一步,稍微牺牲一点数据准确性来给出一个堪用的结果。这里有个非常简单可行的方案,实时流计算只做word count,然后把计算结果存储起来后有个旁路程序扫结果数据,排序后截取TopN,我估计好多人就是怎么做的,架构如下。
这个解决方案优点很明显,因为前面storm就是一个word count,简单可靠。但是如果面对大量的TopN调用,旁路Topn程序就会成为性能瓶颈,因为要涉及到大量的数据查询和排序,而且多一个系统,维护成本也变高了。如果我们想通过纯storm的方式去解决Topn应该怎么做?
在实时热点topn计算过程中,整个计算包含word count和TopN两部分。另外有几个需要特别注意的地方,首先Topn是建立在全量数据上的,最后肯定只能由一个节点输出TopN值,所以需要在前面的计算节点尽可能的减少对后面传送的数据量。其次,像这种业务数据统计基本上都会出现数据热点的问题。
Word count
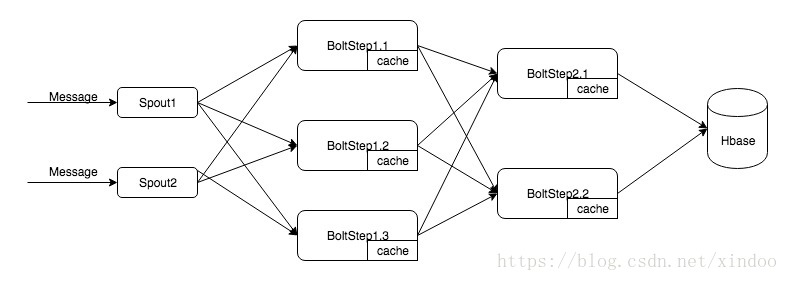
先来看下word count的部分如何做,如何解决数据热点,如何减少对后面的压力,我直接上topo图。
其实在bolt中加cache就可以大大减少发出去的消息量,这里我还有个step2的bolt,是因为我们在实践中发现,如果多个bolt对hbase同可以key写入,虽然可以通过hbase的Increment来保证数据的一直性,但在其过程中要对行加锁,高并发的情况下写入性能会受影响。所以可以先数据流随机shuffle到step1,然后对流量做泄压,然后按key fieldsGrouping到Step2,由step2中的bolt对hbase的数据做get add put的三步操作,没有hbase的加锁操作,grouping后也没并发写一个rowkey的问题。
TopN
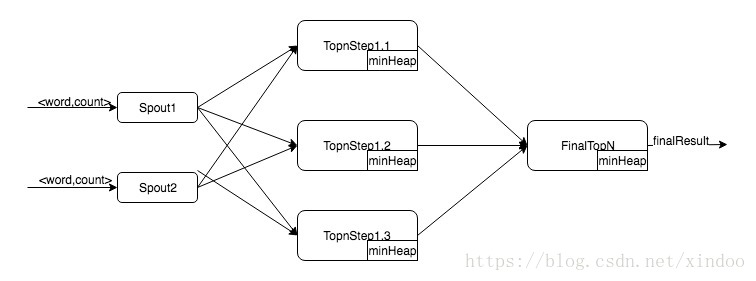
如果我们已经有count好的<词,词频>数据,其实我们并不需要全局排序后截取前n个来实现topn,其实用最小堆就可以大幅度减少TopN的时间复杂度。假设数据量为M,排序的时间复杂度可能到O(MlogM),用最小堆求TopN时间复杂度为O(MlogN),实际情况下N远小于M,这个优化还是非常大的。在实时流TopN中我们也可以用最小堆做性能优化,topo图如下。
在spout方法数据的时候做fieldsGrouping,然后step1中的每个bolt就会维护一部分数据的TopN最小堆,缓冲一段时间后把minHeap里的数据全量发给finalTopN,finalTopn拿到数据后和自己的minHeap已合并就可以拿到正真的topn了。
最终实现
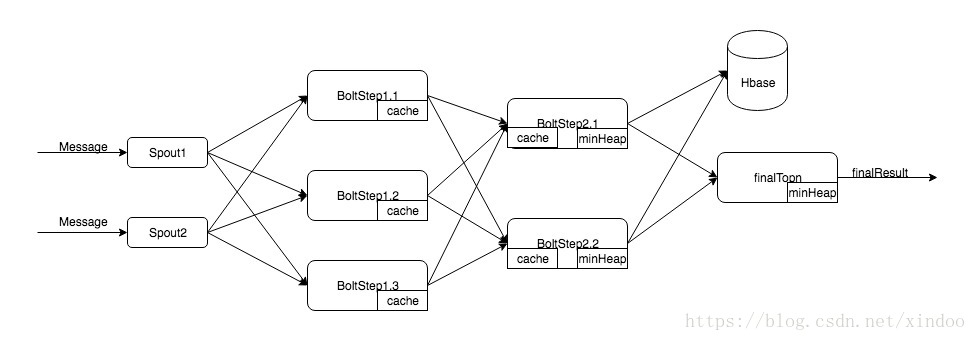
要实现实时热点功能,其实讲上面两个 word count和topn的topo合并起来后就好了,最终的topo如下。
spout收到消息后随机shuffle,step1中的bolt讲一部分统计结果写入cache,待cache失效的时候按key fieldsGrouping到step2,这样可以减少对发出的消息量。 step2中的bolt不仅有个cache还有个minheap,cache中存的是每个key的wordcount,minheap其实是维护的改bolt拿到部分数据的topn。step2中cache数据会失效,失效的时候需要数据更新到hbase中,同时也更新minheap。step2中的minheap超时后,全量数据丢到finalTopn中,再由finalTopn汇总。
在最后一步finalTopn中,同一个key可能由step2多次传下来,所以finalTopn更新其minheap的时候不能只是简单的和根节点做对比,heap中有的话要更新其值。
其它问题
1. 各过程中cache和minheap的失效机制什么设?
cache失效机制我有遇到过相关的例子,一般是数据量或是cache大小触发的,其实这个是做成参数配置的,在不同的业务环境下可能有不同的适合配置。minheap只能以超时时间为触发条件,超时事件设多少得看具体情况了。感觉都是超参,需要调。
2. 如何保证数据不丢?
storm的acker机制就可以保证数据at least once,就是保证数据不丢,但不保证数据不重复,如果真的需要exactly once,还是放弃jstorm吧,可以用flink试试。但我觉得其实在这种非数据强一致性的情况下,ack机制都不需要开,比较storm的ack还是要消耗一定性能的(有看过别人的数据,开启acker要消耗10%以上性能,参考下)。 在我上图topo设计下,如果集群中有一台机器宕了,cache里的数据就全丢了,其实可能损失也不小,但是机器宕机毕竟还是个小概率事件。
3. 最终数据如何尽可能准确?
对一个时间窗口的维护时间越长,越可能拿到全量数据,结果就越准确。这个肯定的最后那个finalTopn的bolt来做了,数据量越大,finalTopnbolt 的挑战也就越大,我觉得可以起多个bolt,按时间窗口Grouping,然后还得对minheap所有数据做持久化,还得支持持久化后的更新,可以对minheap序列化后放到hbase里。