相信即便是Java初学者都应该用过Java中的HashMap和TreeMap,但貌似大多数人都没怎么用过LinkedHashMap,对其知之甚少。因为基本上大多数情况下TreeMap和HashMap都能满足需求,只有在需要map中K-V保持一定顺序时才会用到LinkedHashMap。所以保序是LinkedHashMap较HashMap和TreeMap最大的特点,至于保什么序后面会详细讲解。
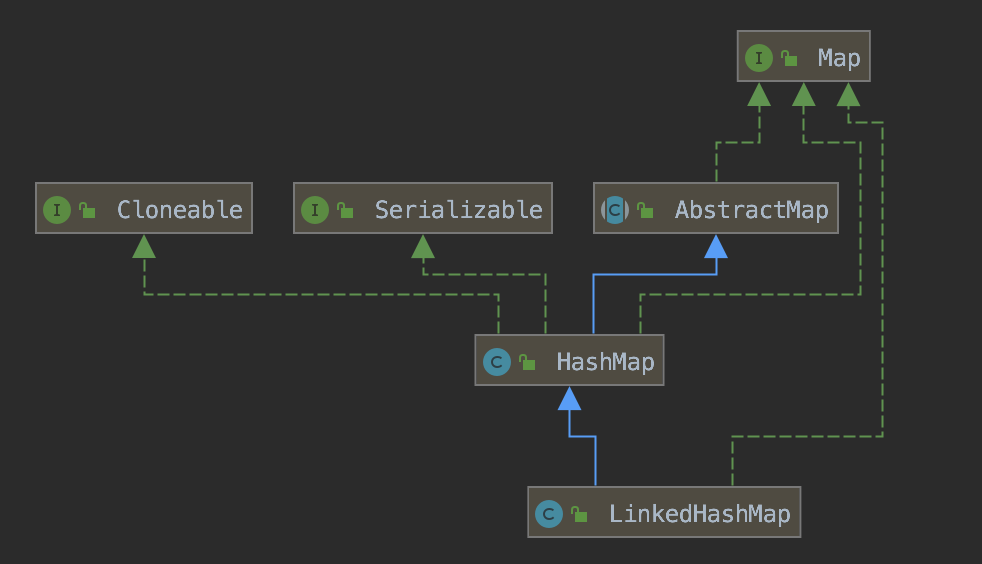
从类图其实可以看出来,LinkedHashMap其实是完全继承于HashMap的,甚至好多地方干脆复用了HashMap的源码。其实可以认为HashMap的功能是LinkedHashMap的子集,HashMap可以做的LinkedHashMap都可以做。
如何使用
其使用方式和HashMap一致,但默认是能保持插入顺序的,所以使用Iterator比例keySet或者entrySet时可以得到和插入顺序一致的结果。
public static void main(String[] args) {
Map<Integer, Integer> map = new LinkedHashMap<>();
map.put(4,2);
map.put(2,4);
map.put(3,5);
Iterator<Integer> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
它不仅仅能保持插入顺序,也可以看元素是否访问调整顺序,下面代码和上面代码的区别是多了构造函数和一个元素的get。但迭代的结果完全不同。LinkedHashMap对访问调序的支持为简单实现LRUCache奠定了基础。
public static void main(String[] args) {
Map<Integer, Integer> map = new LinkedHashMap<>(8, (float)0.75, true);
map.put(4,2);
map.put(2,4);
map.put(3,5);
map.get(4);
Iterator<Integer> iterator = map.keySet().iterator();
while (iterator.hasNext()) {
System.out.println(iterator.next());
}
}
实现

从类图其实可以看出来,LinkedHashMap其实是完全继承于HashMap的,甚至好多地方干脆复用了HashMap的源码。其实可以认为HashMap的功能是LinkedHashMap的子集,HashMap可以做的LinkedHashMap都可以做。
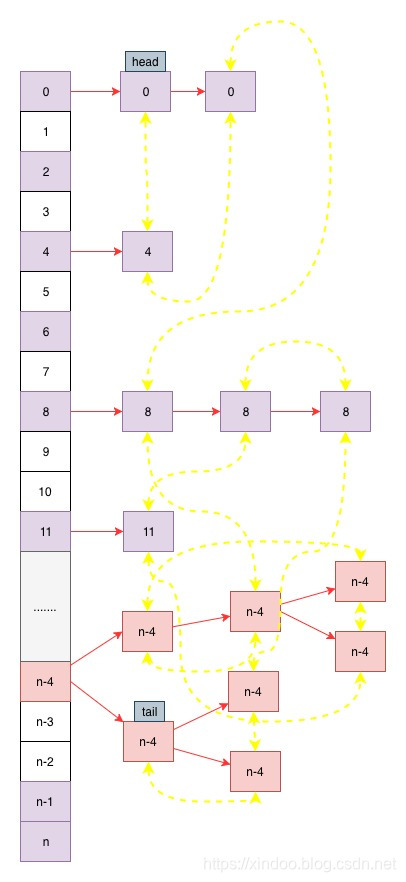
其实说白了,LinkedHashMap其实就是在HashMap+链表,就是用双链表把HashMap中的每个Node串起来,可以看如下示意图,黄色线条代表链表中的关系,主体结构还是HashMap中的结构,关于HashMap可以看我另一篇博客Java HashMap源码浅析 。所以较HashMap的源码,LinkedHashMap就是多加了一些双链表的操作(插入、删除、节点挪动到尾部……)。
源码
初始化

LinkedHashMap的构造函数和HashMap的差不多类似,但多出来上图中的最后一个,其中参数多了一个boolean 类型的accessOrder,这个其实是否在节点被访问和变更后将其移动到双向链表的末尾,这也是文章最后实现LRUCache的关键参数。
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
Entry
Entry继承自HashMap.Node<K,V>,就是在HashMap.Node<K,V>的基础上只添加了双向链表的前后指针,代码很简单如下。
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
put & get & resize & removeNode
其实LinkedHashMap中没有自己的put & get & resize & removeNode方法,完全是继承了HashMap中的方法。那肯定你也会好奇,LinkedHashMap中肯定每次增删改查总是会涉及到对双链表的操作,这是如何实现的?这个时候我们需要回到HashMap的源码中去。
// Callbacks to allow LinkedHashMap post-actions
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
如果你之前看HashMap的代码,你可能注意到了这三个没有实现的方法,你可能会很好奇他们有什么用。这三个方法在HashMap的各种操作中被用到了,看名字和注释也能看出来是在节点操作后做一些工作。可惜在HashMap中没用,你不看LinkedHashMap的源码肯定会感到莫名其妙的。
void afterNodeRemoval(Node<K,V> e) { // unlink
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.before = p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a == null)
tail = b;
else
a.before = b;
}
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
afterNodeRemoval()就是在Map中元素被移除后也移除双链表中相应的元素。 afterNodeInsertion()就是额外在双链表尾部插入新元素。但afterNodeAccess()就比较奇怪了,它是把某个元素挪动到队列的尾部,这有啥用?
afterNodeAccess分别在putVal、merge、replace……总之所有有变动的地方调用,这以为着map中最新变动的值肯定是会在链表尾部,相反最旧的就在头部了(需要在构造函数中开启accessOrder)。
在afterNodeInsertion()中我们还看到了removeEldestEntry(first),就是在插入新元素后移除最老的元素。 LinkedHashMap中默认是false,也就是不移除。如果我们继承了LinkedHashMap并对其重载,然后结合afterNodeAccess,就可以对最近最久未访问的元素做清理,不就是有个LRUCache了吗。
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
```
### LinkedHashMap如何实现遍历时的保序
开头说过,LinkedHashMap和HashMap最大的一个区别就是前者能实现遍历的保序。可以按插入顺序或者最久访问顺序遍历,如何实现的?其实看下keySet() values() entrySet()这几个key value k-v遍历方法就知道了。HashMap中无法保存顺序信息,但双链表可以啊,所以为了获取顺序信息,它们不是HashMap中从map中获取数据,而是从双向链表中获取。
```java
public Set<K> keySet() {
Set<K> ks = keySet;
if (ks == null) {
ks = new LinkedKeySet();
keySet = ks;
}
return ks;
}
final class LinkedKeySet extends AbstractSet<K> {
public final int size() { return size; }
public final void clear() { LinkedHashMap.this.clear(); }
public final Iterator<K> iterator() {
return new LinkedKeyIterator();
}
public final boolean contains(Object o) { return containsKey(o); }
public final boolean remove(Object key) {
return removeNode(hash(key), key, null, false, true) != null;
}
public final Spliterator<K> spliterator() {
return Spliterators.spliterator(this, Spliterator.SIZED |
Spliterator.ORDERED |
Spliterator.DISTINCT);
}
public final void forEach(Consumer<? super K> action) {
if (action == null)
throw new NullPointerException();
int mc = modCount;
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after)
action.accept(e.key);
if (modCount != mc)
throw new ConcurrentModificationException();
}
}
values() entrySet()方法实现类似,就不全贴了。
LRUCache
上文提到多次LRUCache,其中LRU是Least Recently Used的缩写,其实就是想在有限的存储空间里保留更多有价值数据的一种方式。其实现的依旧就是最佳被使用的数据将来还被使用的概率更高,这个现象在计算机领域非常明显,很多优化就是基于此的。LRUCache就是这样一种存储的实现,它的难点就在于如何高效地剔除掉最旧的数据,以及如何维护数据的新旧度。
有了LinkedHashMap后,我们就可以很简单的实现一个LRUCache。依赖Linked和HashMap的结合,查询时可以从HashMap中以O(1)的时间复杂度查询,数据过期也可以用O(1)的时间复杂度从Linked中删除。LRUCache就是HashMap和Linked二者完美结合的体现。
一个LRUCache的完整代码如下,没错 是完整的代码,就是这么简单,主要的逻辑LinkedHashMap里都已经帮你实现了,你只需要稍微封装下就可以了。其实只需要重载下HashMap中的removeEldestEntry()方法就行,这个方法会在新节点插入或者旧节点访问后被调用。
import java.util.LinkedHashMap;
import java.util.Map;
public class LRUCache<K,V> extends LinkedHashMap<K,V> {
private int maxCap;
@Override
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return size() > this.maxCap;
}
public LRUCache(int capacity) {
super(capacity, (float)0.75, true);
this.maxCap = capacity;
}
}