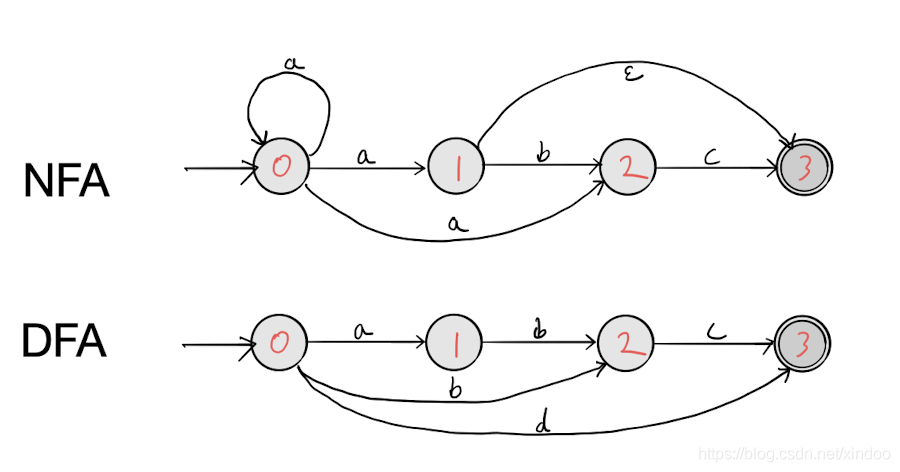
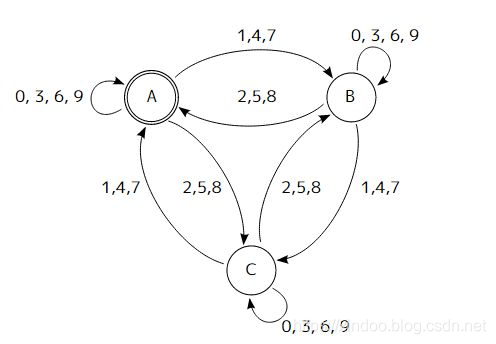
我之前一直自诩精通正则表达式(毕竟我实现过正则引擎),但关于正则表达式有几个特殊用法我一直都不熟,一来是用的少,二来确实也没花心思学过。正好这两天有需要用到预查的功能,索性就学习整理出今天的博文。
介绍下今天的4位主角 ?=、?<=、?!、?<!,估计大多数人都面生。我们小学二年级就知道 正则表达式 是用来做字符串匹配的,核心在于匹配 二字。以往我们见到的正则表达式都是直接匹配出某些内容,而和?=、?<=、?!、?<!相关的正则表达式却只是辅助匹配,它们本身不会匹配出任何内容,像这类的正则表达式我们也称之为零宽断言,它们存在的意义也只是为了定位。

举个例子大家就清楚了,假设你让你去书架上找本白色封面200多页的小说,这句话就是用来匹配书的模式。当然书架上白色封面200多页的小说 有好多本,我想进一步缩小范围。我想要放在《编译原理》左边的白色封面200多页的小说,这里我提到了《编译原理》找本书,但是我并不想要它,它只是起到定位作用。在正则表达式中起定位作用但不匹配的,就是今天要讲的?=、?<=、?!、?<!。
?=
我们挨个来看下这几个正则语法的用法,首先是?=,用法是exp1(?=exp2),查找出现在exp2前面的exp1,exp2是不会出现在结果里的,如下图。
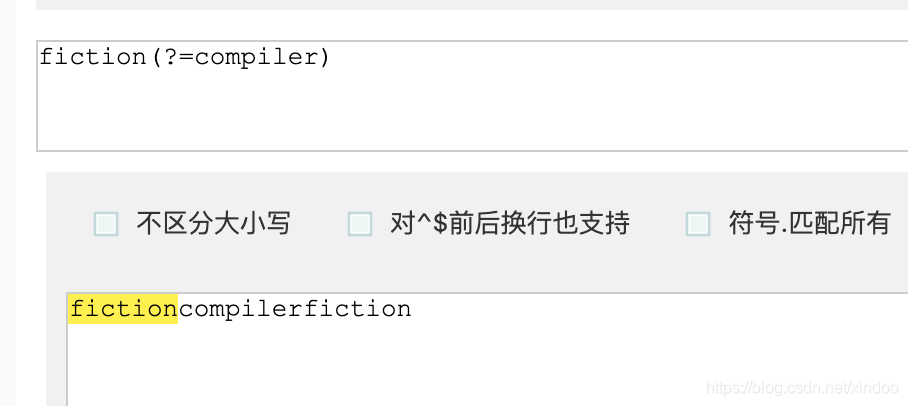
这里我特意用了fiction和compiler俩词,小说和编译,字符串中有两个fiction,分别在compiler的左右两侧,fiction(?=compiler)只匹配到了第一个fiction,(?=compiler)对其做了定位限制。 和上面所举的例子对应上就是 找一下放在《编译原理》左边的小说。
?!
?!和?=是一对,?!是?=的否定语义,用法是exp1(?!exp2),其意义是不是出现在exp2前面的exp1。我们直接将上图中的 ?=改成?!,那它就只会匹配到右边的fiction了,对应的就是不在《编译原理》左边的小说。

?!和?=是按照右侧模式去定位,正则表达式作为一个设计成熟的工具,必然也会有与之对应的左侧定位,那就是 ?<= 和 ?<!,同理它俩也是一对。
?<=
?<= 和 ?= 用法恰好反过来,?<=要放在匹配内容的前面,比如:(?<=exp2)exp1,其作用是匹配exp2后面的exp1,我们还是以compiler和fiction为例,这次我们将字符串中的compiler和fiction换个位置,正则表达式也换成?<=,其作用就变成了查找放在《编译原理》右边的小说

?<!
?<! 是 ?<= 的否定模式,用法同?<=,(?<!exp2)exp1,其作用是匹配不在exp2后面的exp1,用法我就不再赘述了,直接看图,该正则表达式没有匹配第一个fiction,而是匹配到了第二个fiction。 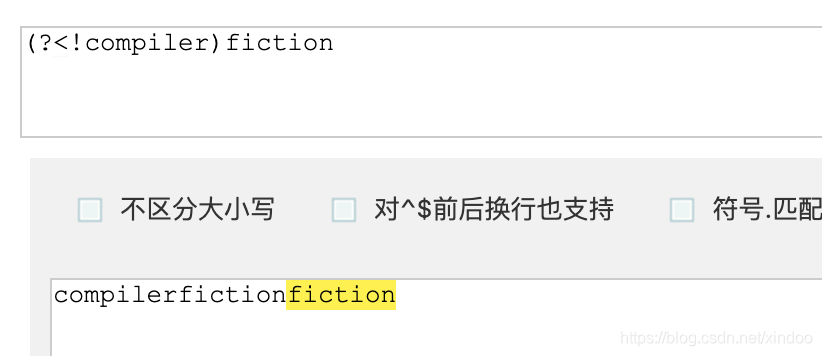
结语
正则表达式是一个极其有用的工具,我个人经历,精通正则表达式可以为日常工作提效不少,比如简单的日志清晰,简单的数据统计…… 正则表达式加其他linux命令行工具,可以提效非常多。举个不那么正经的例子,比如我要下个美剧,视频网站上几十集都是分开的链接,正常人估计都是复制粘贴到下载器,重复20多次,不仅麻烦而且可能有遗漏或重复。而我的操作,打开网页源码 正则表达式一匹配,批量复制粘贴,完事。
另外正则表达式也是非常有趣的工具,不信你可以看下我之前写的几篇相关博客。
用正则表达式来检测一个数是否是素数
用正则表达式匹配3的任意倍数
手撸正则引擎