同一份逻辑,不同人的实现的代码性能会出现数量级的差异; 同一份代码,你可能微调几个字符或者某行代码的顺序,就会有数倍的性能提升;同一份代码,也可能在不同处理器上运行也会有几倍的性能差异;十倍程序员不是只存在于传说中,可能在我们的周围也比比皆是。十倍体现在程序员的方法面面,而代码性能却是其中最直观的一面。
本文是《如何写出高性能代码》系列的第四篇,本文将告诉你数据访问会怎么样影响到程序的性能,以及如何通过变更数据访问的方式提升程序的性能。
数据访问速度为什么会影响到程序的性能?
程序的运行的每一个可以简化为这样一个三步模型:第一步,读数据(当然也有部分数据是别的地方法发过来的);第二步,对数据做处理;第三步,将处理完的结果写入存储器。这里我将这三步骤简称为 读算写。 实际上真实的CPU指令执行过程会稍微复杂有些,但实际上也是这三个步骤。 而一个复杂的程序包含无数个CPU指令,如果读取或者写入数据太慢,必然会影响到程序的性能。

为了能更直观一点,我这里将程序执行的流程比作是大厨做菜,大厨的工作流程就是取原始食材,然后对食材进行加工(煎烤烹炸煮),最后出锅上菜。影响大厨出菜速度的因素除了加工过程之前,获取食材的耗时也会影响到大厨出菜速度。有些食材就在手边,可以很快获取到,但有些食材可能在冷库、甚至在菜市场,获取就很不方便了。
CPU犹如大厨,而数据就是CPU的食材,寄存器里的数据就是CPU手边的食材,内存的数据就是在冷库的食材,固态硬盘(SSD)上的数据是还在菜市场的食材,机械硬盘(HDD)上的数据犹如还在地里生长的菜…… 如果CPU在运行程序时,如果拿不到所需要的数据,它也只能等在那儿浪费时间了。
数据访问速度对程序性能有多大影响?
不同存储器数据读取和写入的时延相差极大,鉴于大多数场景下,我们都是读取数据,我们就只拿数据读取为例,最快的寄存器和最慢的机械磁盘,随机读写的时延相差百万倍。可能你没有直观概念,我们还是拿厨师做个类比。
假设厨师要做一道西红柿炒鸡蛋,如果食材都有人备好的话,只需要十来秒食材就能下锅炒制。 我们把这个时间比作是CPU从寄存器里取到数据的时间。然而如果是CPU从磁盘获取数据的话,所耗费的时间相当于厨师自己种出西红柿或者养小鸡下蛋了(3-4个月)。由此可见,从错误的存储设备上获取数据,会极大影响程序的运行速度。
再说一个我们之前在生产环境遇到的实际案例,我们在生产环境也出过故障。原因是这样的,我们有个服务容器化改造的时候,和上游服务没有部署在同一个机房,跨机房虽然只会增加1ms的时延,但他们服务代码写的有问题,有个接口批量串行调另外一个服务,串行累加导致接口时延增加上百ms。 本来没有性能问题的服务,就因为迁移了机房,导致性能出现了问题……
各存储器性能差异
实际上在编码的时候,遇到的存储设备多种多样,寄存器、内存、磁盘、网络存储……,每种设备都有自己的特点。只有认识到各种存储器之间的差异,我们才能在正确的场景下使用合适的存储器。以下表格就是各类常见存储设备的随机读时延参考数据……
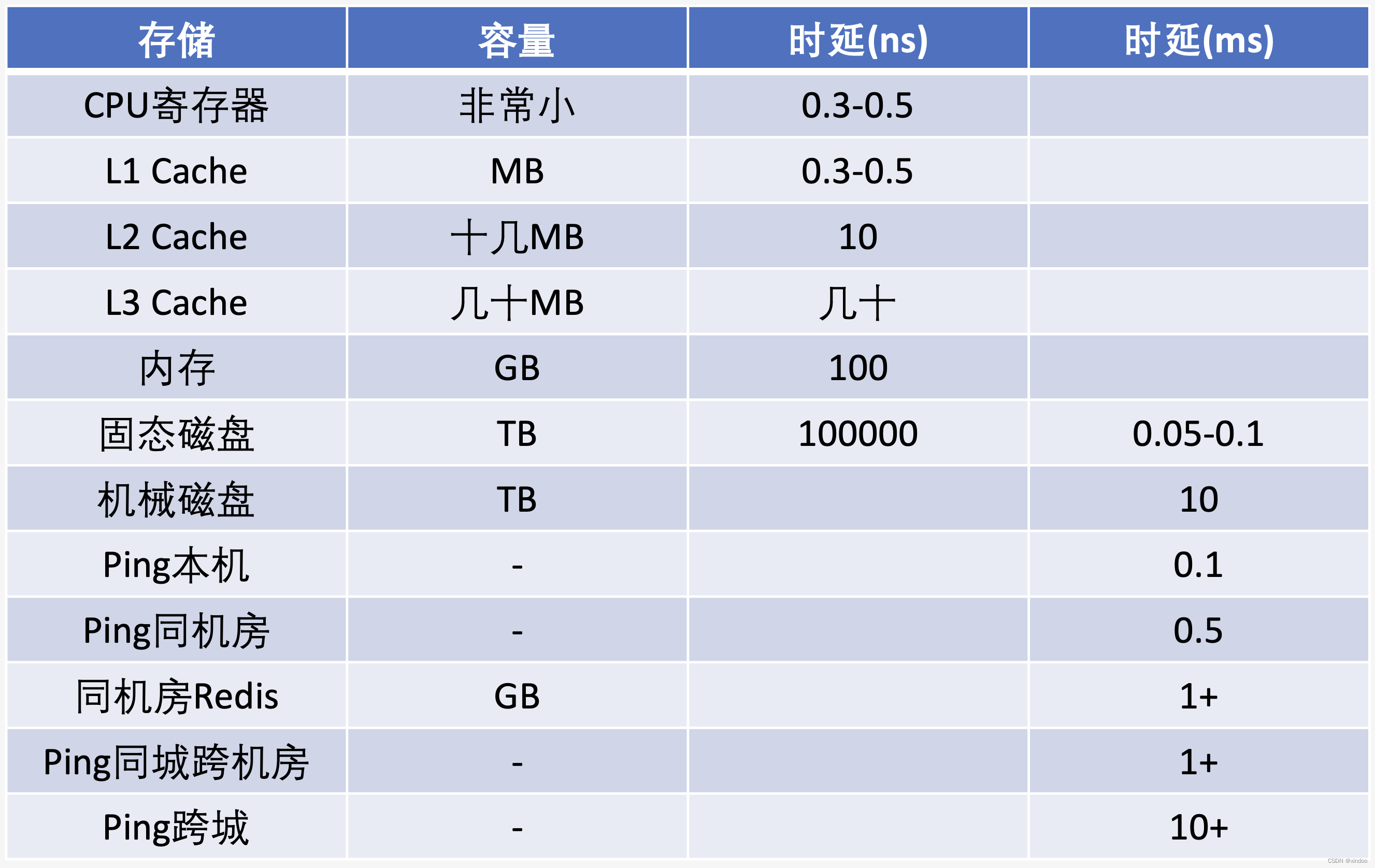
备注:以上数据在不同硬件设备会有出入,这里只是为了展示其差异性,不代表准确值,准确信息请参考硬件手册。
虽然日常我们觉得内存的读取速度已经很非常快了,日常写代码的时候遇到啥数据获取比较慢,加个内存缓存速度简直就起飞了。但内存的访问速度相对于CPU运行速度来说还是太慢,读取一次内存的时间,都够CPU执行几百条指令了,所以现代CPU都对内存加了缓存。
如何减小数据访问时延对性能的影响?
减少数据访问时延对性能的影响也很简单,那就是把数据尽可能放到最快的存储介质上。然而,存取速度、容量、价格三者之间有着不可调和的矛盾,简单来说就是 速度越快容量越小但价格越贵,反之容量越大速度越慢而价格越便宜。
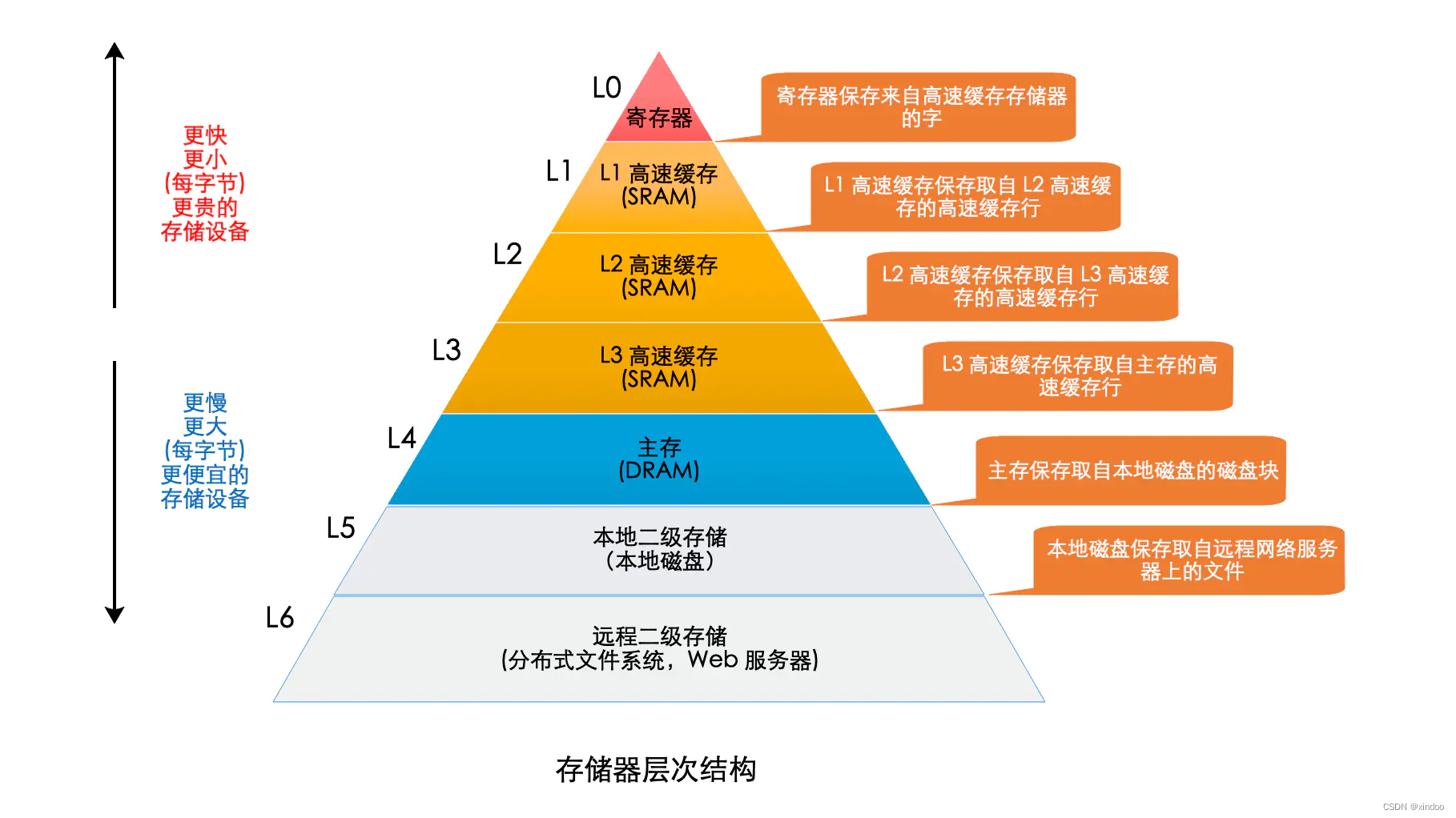
世界总是那么巧秒,仿佛一切早被安排好,我们并不需要把所有的数据都放在最快的存储介质上。 还记得我们在第二篇(巧用数据特性)[https://blog.csdn.net/xindoo/article/details/123941141] 提到的数据局部性吗! 局部性分两种,空间局部性和时间局部性。
- 时间局部性: 如果一份某个时刻数据被访问过,那不久之后这份数据会被再次访问到。
- 空间局部性: 如果某个存储元被访问过,大概率那不久之后,其附近的存储单元也会被访问。
总结下这两点就是,程序大部分时间只会集中访问很小的一部分数据。 这意味着我们可以用较小的存储空间覆盖到大部分被访问的数据。 说直接点就是,我们可以加缓存。 实际上,不管是计算机硬件、数据库、还是业务系统,到处都充斥着缓存。甚至你写下的每一行代码,在机器上运行时都用到了缓存,不知道大家有没有关注过CPU,CPU有个参数,就是缓存大小,我们以intel酷睿i7-12650HX 为例,它就有24MB的三级缓存,这个缓存就是CPU到内存之间的缓存。 只不过现代计算机将底层的细节屏蔽掉了而已,我们日常不太可能主要的到。
在我们自己写代码的时候,也可以加缓存来提升程序性能。举个最近的我们在系统中遇到的例子,我们最新在做数据权限相关的功能,不同的员工在我们系统中有不同的权限,所以他们看到的数据也应该是不同的。我们的实现方式是每个用户请求系统的时候,首先获取到该用户所有的权限列表,然后把所有在权限列表中的数据展示出来。
因为每个人的权限列表比较大,所以权限接口的性能不怎么样,每次请求耗时也比较长。所以,我们直接给这个接口的数据加了缓存,优先从缓存里取,取不到再调接口,极大提升了程序性能。当然因为权限数据也不会经常变动,所以也不用太考虑数据滞后导致的后果。另外,我们缓存数据只加了几分钟,因为一个用户单次使用我们系统时长也就持续几分钟,过几分钟后数据过期缓存空间也会自动释放,达到节省空间的目的。
我在上大学那会,笔记本电脑还是标配机械硬盘的年代,那时候电脑永久了会很卡,后来了解到换装SSD会提升电脑性能,那个时候SSD还挺贵的,普通笔本都不会标配SSD后来我攒半个月的生活费给自己笔记本替换了一块120g的SSD,电脑的运行速度就有明显的提升,本质上还是因为SSD的随机访问时延比机械硬盘快上百倍的原因。 之前某大厂号称将mysql性能提升了上百倍,其实也是基于SSD做的很多查询优化。
缓存不是银弹
银弹(英文:Silver Bullet),指由纯银质或镀银的子弹。在欧洲民间传说及19世纪以来哥特小说风潮的影响下,银色子弹往往被描绘成具有驱魔功效的武器,是针对狼人、吸血鬼等超自然怪物的特效武器。后来也被比喻为具有极端有效性的解决方法,作为杀手锏、最强杀招、王牌等的代称。

这里特别提醒下,缓存不是万能的,缓存其实是有副作用的,那就是数据的有效性很难得到保证。缓存其实里面放的是旧数据,当前时刻数据是不是还是这样的?不确定,也许数据早就变了,所以使用缓存时必须要关注缓存数据有效性问题。如果缓存时间过久,数据失效的可能性能,数据不一致导致的风险也就越大。 如果缓存时间过短,因为经常需要获取原始数据,缓存存在意义也就越小。所以在使用缓存必须要做出数据不一致和性能之间的权衡(trade-off),你需要正确评估数据的时效性,对缓存设置合理的过期策略。
上文说到其实我们写下的每一行代码都用到了缓存,现在大家已经都知道这个缓存其实就是CPU的Cache。CPU的Cache也是有明显的副作用的,我们在写多线程代码的时候也不得不关注到,那就是多核CPU之间数据一致性的问题。因为CPU Cache的存在,我们写多线程代码时不得不考虑数据同步的问题,导致多线程的代码很难编写,出了问题也很难排查。
有个面试八股文题目其实就很容易说明这个问题——多线程计数器,多线程去操作计数器,累加统计数据,如何保证数据统计的准确性。如果只是简单使用cnt++实现,这里就会遇到多核CPU缓存导致的数据不一致性,具体原理这里不再解释,反正结果就是统计出来的数据会比真是数据少。 正确的做法就是,你必须在累加的过程中加多线程同步的机制,保证同一时刻只可能有一个线程在操作,操作完之后也能保证数据能写回内存,在java中必须使用锁或者原子类实现。而这对于编程新手而言又是一道门槛。
总结
数据访问是任何程序不可或缺的一部分,甚至对大多数程序而言时间都耗费在了数据访问的过程上,所以只要优化了这部分的耗时,程序的性能必然能得到提升。
本文全部内容就到这了,下一篇,我们将继续探讨下性能优化到极致该怎么做,敬请期待!!另外,有兴趣也可以查阅下之前的几篇文章。