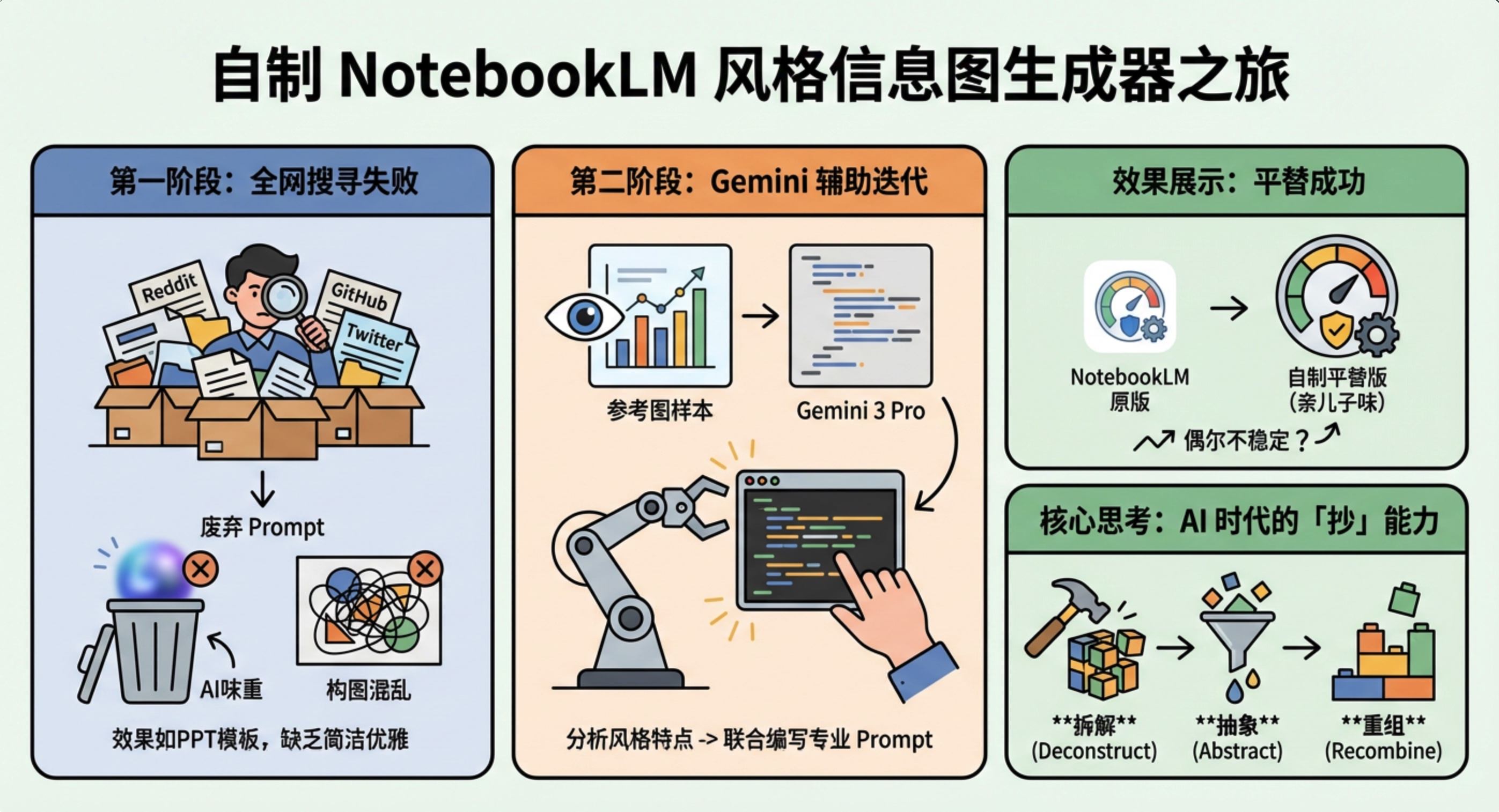
OpenAI在去年推出的GPT-4V已经支持了多模态识别,但一直仅限于图片输入,不支持视频。相比之下,Google的Gemini早已支持视频识别。最近,我司业务场景中出现了一个需要识别视频的需求,而我们只采购了GPT-4o模型。这就引发了一个问题:如何使用GPT-4o完成对视频的处理?
经过研究一些教程后,我找到了一个解决这个问题的可行方法。这种方法包括两个步骤:首先,将视频拆分成一系列关键帧图像;然后,将这些图像输入GPT-4o进行分析,从而完成对整个视频的解读。 实现起来很简单,这里我特意找了一段猫和老鼠的视频片段,来复现下这个实现,具体代码如下:
from IPython.display import display, Image
# 这里我们需要用到cv2和base64
import cv2
import base64
import time
from openai import OpenAI
client = OpenAI()接下来是视频关键帧的抽取。为了减少token消耗,我采用了两种方式削减信息量:
- 丢弃大部分画面,每秒只保留一帧;
- 将图片分辨率缩减至360p,以减小图片大小。
这里额外解释一下为什么要转成base64编码的数据。OpenAI接口支持两种传递图片的方式:一种是直接传可公开访问的图片URL,但我们没有;另一种是将图片直接base64编码后传递,所以我们只能选择后者。
video = cv2.VideoCapture("data/tom_and_jerry.mp4")
base64Frames = []
fps = video.get(cv2.CAP_PROP_FPS)
frame_jump = int(fps)
frame_count = 0
# 定义目标尺寸
target_width = 640
target_height = 320
while video.isOpened():
success, frame = video.read()
if not success:
break
# 一秒钟保存一帧
if frame_count % frame_jump == 0:
resized_frame = cv2.resize(frame, (target_width, target_height))
_, buffer = cv2.imencode(".jpg", resized_frame)
base64Frames.append(base64.b64encode(buffer).decode("utf-8"))
frame_count += 1
video.release()
print(len(base64Frames), "frames read.")接下来是最关键的部分:调用GPT-4o来解析图片。这个函数将处理我们先前提取的视频帧,利用GPT-4o模型分析这些图像。它会生成一个详细的视频内容描述,帮助我们理解整个视频的剧情脉络。
def vision(frames):
PROMPT_MESSAGES = [
{
"role": "user",
"content": [
{
"type": "text",
"text":
f"""
这些图片是从视频中按先后顺序截取出来的,截取的时间间隔是1s,总共{len(frames)}张,请根据这些画面信息,用中文详细描述下视频的剧情。
"""
},
*[{
"type": "image_url",
"image_url": {
"url": 'data:image/jpeg;base64,' + frame,
}
} for frame in frames]
],
},
]
params = {
"model": "gpt-4o",
"messages": PROMPT_MESSAGES,
"max_tokens": 2000,
"temperature": 0.7
}
result = client.chat.completions.create(**params)
return result.choices[0].message.content最后,我们调用先前定义的 vision 函数来处理提取的视频帧,并获得相应的分析结果。
result = vision(base64Frames)
print(result)得到的结果如下,剧情的描述还是相当准确的。 这个实验结果证明了我们的方法是可行的。通过将视频拆分成关键帧并使用GPT-4o进行分析,我们成功地对整个视频内容进行了准确的描述。这种方法不仅解决了我们无法直接处理视频的限制,还展示了GPT-4o在多模态任务中的强大能力。
这段视频似乎是汤姆和杰瑞的经典动画片。
剧情开始时,一个女人正在用扫帚打扫地板,她穿着高跟鞋。接着,一只小白鼠(可能是杰瑞的朋友)出现在扫帚旁边。随后,汤姆猫出现,试图用扫帚抓住小白鼠,但小白鼠灵活地避开了。
然后,汤姆展开追逐,抓住了小白鼠,但杰瑞及时赶到,与汤姆展开对抗。汤姆试图打开一个门,但被困在了门后。女人用扫帚打了汤姆的头,并责备他为什么还在找麻烦。
汤姆用手指着小白鼠,试图证明自己的行为是正当的,但女人显然不买账。汤姆因此被赶出屋外,并浑身沾满油漆。小白鼠发现了一瓶鞋油,似乎在计划什么。
最后,汤姆装扮成白色的猫,试图重新回到屋内,并假装自己是“会跳舞的猫”。女人对他的伎俩似乎感到满意,进行了表扬,但小白鼠却看穿了汤姆的伪装。视频以汤姆和小白鼠的搞笑互动结束,最后画面出现“结束”的字样。
总体来看,这段视频展示了汤姆和杰瑞的经典追逐和幽默桥段,充满了滑稽和欢乐。尽管GPT-4o官方并未提供视频分析功能,我们仍可通过这种巧妙的变通方法实现视频理解。我个人认为这种方法相当有趣。完整的代码已在GitHub上公开,链接为https://github.com/xindoo/openai-examples/blob/main/vision_for_video.ipynb。