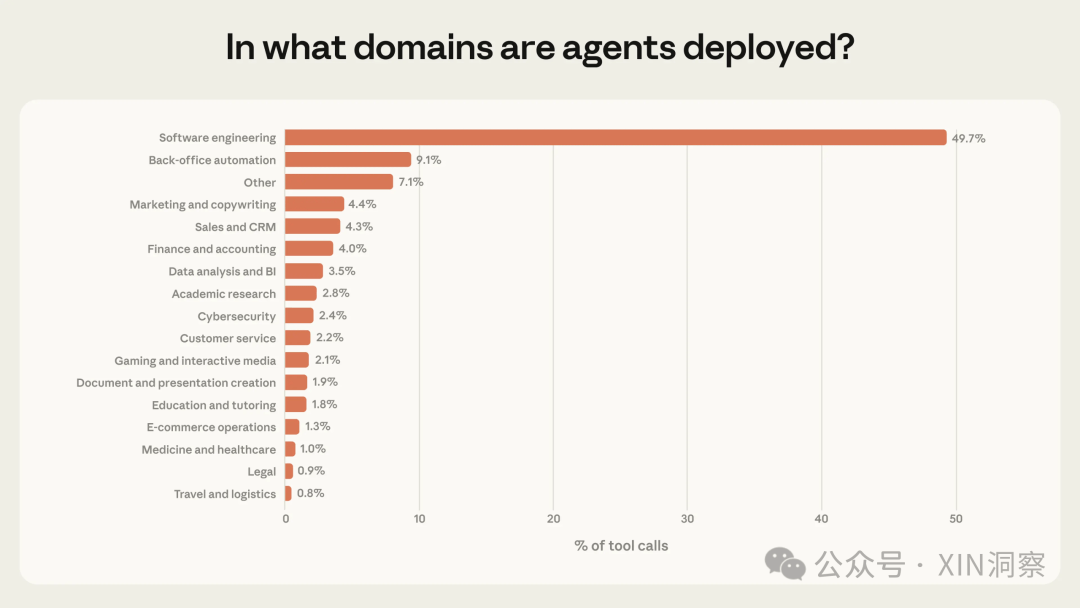
我在前一段时间翻译开源了Google的新书《Agentic Design Patterns》,这是一本系统性介绍AI Agent构建模式的书籍,非常推荐大家阅读下,我在github中也提供了英文原版和中文版的精排版电子书,可以直接下载,具体可以看我github项目地址https://github.com/xindoo/agentic-design-patterns。
最近,我用 n8n 为这本书开发了一个问答机器人。机器人内置了全书内容,掌握每个细节,可以作为你的阅读助手。无论你想深入了解某个设计模式,还是对书中概念有疑问,它都能提供详细解答和指导。 另外我又通过 n8n 的 GitHub 节点,让机器人与代码库保持实时同步。后续的翻译更新会自动同步到机器人,无需手动维护。
我已将这个机器人集成到翻译项目的中文官网https://adp.xindoo.xyz/ 中,你可以直接点击右下角唤起。欢迎大家体验,希望它能为你阅读这本书提供帮助。

接下来,我将详细介绍如何使用 n8n 搭建这样一个问答机器人,以及如何将其集成到的 GitHub 页面中。整个过程并不复杂,即使你是第一次接触 n8n 也能快速上手。
前置依赖
- n8n 是目前国外最流行的自动化平台之一,通过直观的可视化节点编辑器,让用户可以像搭积木一样连接各种应用和服务。它支持超过 400 种集成,涵盖了从数据库、API、云服务到各类 SaaS 应用的方方面面。n8n 完全开源且可自部署,你可以将其部署在自己的服务器上,确保数据安全和隐私。它还提供强大的 JavaScript 自定义能力,让开发者可以编写自定义逻辑来处理复杂的业务场景。此外,n8n 拥有活跃的社区和丰富的模板库,用户可以直接使用或参考他人分享的工作流模板,大大降低了学习成本,让任何人都能快速构建出符合自己需求的自动化工作流。
首先你肯定需要一个n8n实例,可以自己部署,也可以直接使用n8n的云服务。如果选择自己部署,可以使用Docker或者直接在服务器上安装。除此之外,你还需要准备好自己的AI API Key,用于调用大语言模型(也不一定用openai、国内阿里字节都可以)。另外,你可能还需要一个向量数据库,来存储书籍内容和实现语义搜索。如果你没有自己的向量数据库,也可以使用n8n内置的Pinecone或Supabase等向量数据库服务。
整个机器人的构建分为三个关键步骤:数据写入向量数据库、问答功能实现和网页集成。下面我会详细介绍每个步骤的具体实现方法。
数据写入向量数据库
要让机器人能够准确回答问题,首先需要将书籍内容存储到向量数据库中。整个过程主要包括以下几个步骤:
- 获取GitHub仓库内容: 使用n8n的GitHub节点,通过API获取仓库中的文档文件。我这里设置监听项目的release事件,只要项目库又发新版本,就会自动同步最新的翻译内容。
- 文本分块处理: 将获取到的文档内容进行分块(Chunking)处理。这一步很关键,需要将长文本切分成合适大小的片段,既要保证语义完整性,又要控制每个片段的长度。通常建议每个分块在500-1000字符之间。
- 生成向量嵌入: 使用OpenAI的Embedding API将文本分块转换为向量表示。n8n提供了embeding节点,可以直接调用像openai的text-embedding等模型生成嵌入向量。
- 存储到向量数据库: 将生成的向量连同原始文本一起存储到向量数据库中。n8n支持多种向量数据库,如Pinecone、Qdrant、Supabase等。存储时建议添加元数据,比如文档来源、章节信息等,便于后续检索和追溯。
虽然步骤看起来很多,但 n8n 已经为我们封装好了向量存储(Vector Store)节点。你只需配置数据库连接、Embedding 模型和文本分块策略,n8n 就会自动完成文本向量化和存储工作,大大简化了开发流程。此外,你还可以在 Text Splitter 节点中根据需求调整分块大小和重叠度,以获得更好的检索效果。
这里分享一个实用技巧。有经验的同学可能已经看出来了,这本质上是一个 RAG 系统。RAG 的劣势在于难以把握全局信息。为了解决这个问题,我采用了一个巧妙的方法:将项目的 README.md 文件作为独立的文档片段完整存入向量数据库,因为它包含了完整的项目介绍。同时,我在 AI 的系统提示词中也预设了一些项目全局信息。这样当用户提出"这本书主要讲什么"之类的全局性问题时,AI 就能从这个完整摘要中获取信息,给出更全面的回答。
再回到具体实现,这里我使用了基于 Postgress 的 PGVector ,它是 PostgreSQL 的一个扩展,可以直接在关系数据库中存储和检索向量数据。相比专门的向量数据库,PGVector 的优势在于可以与现有的 PostgreSQL 数据库无缝集成,减少了系统的复杂度。配置过程也很简单,只需要在 n8n 的 Vector Store 节点中选择 PGVector,填入数据库连接信息即可。
具体流程如下图所示:
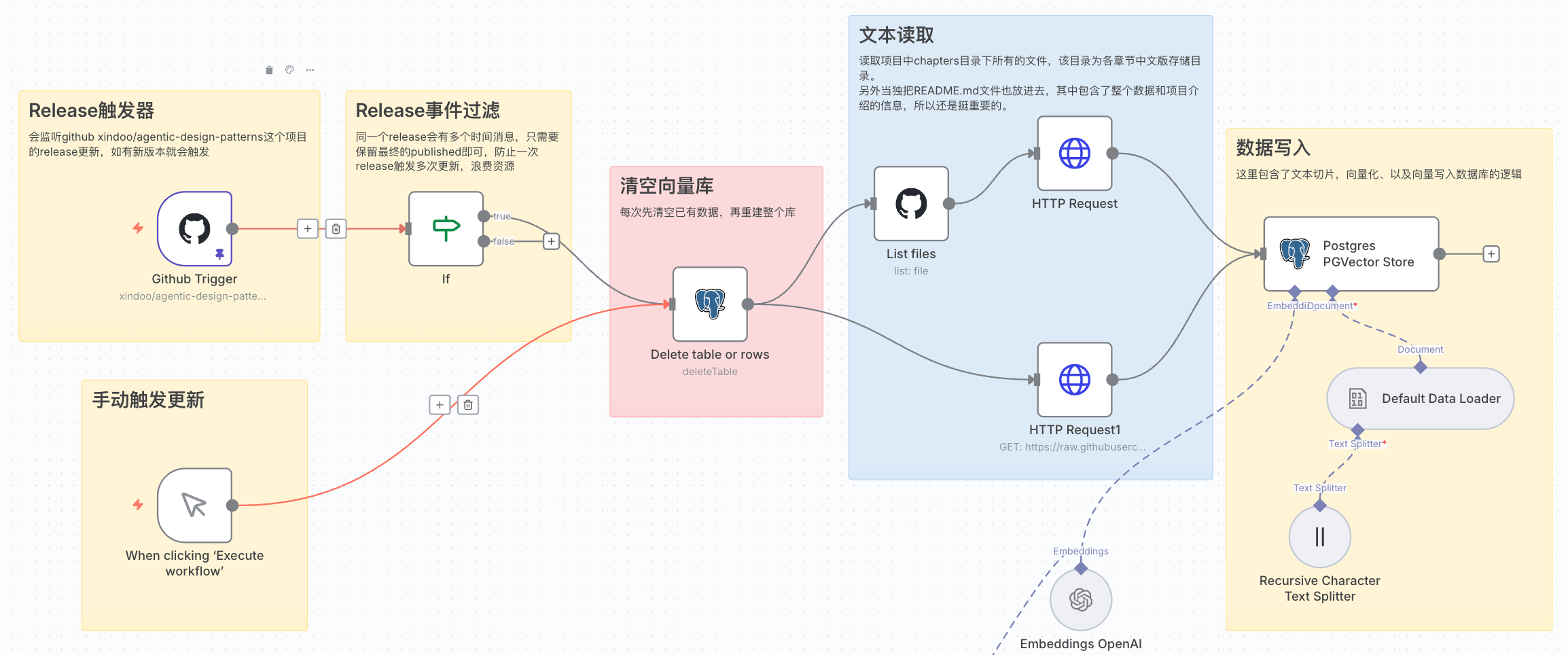
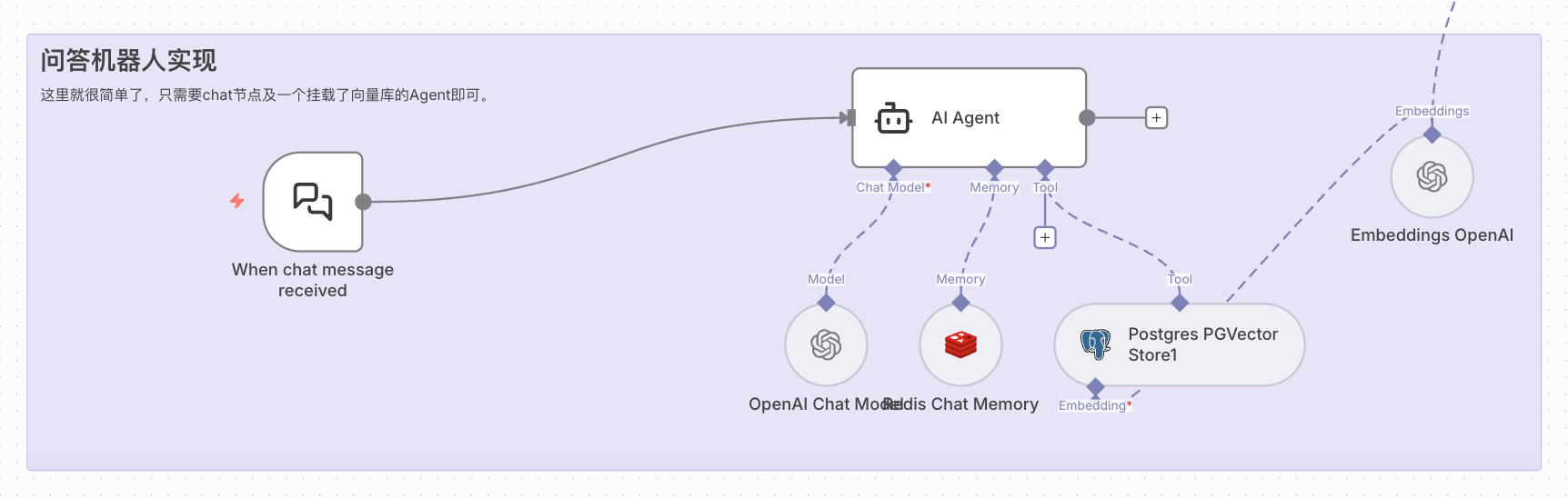
问答机器人的实现
用户提问后,机器人通过以下步骤生成回答:
- 接收用户问题: 通过n8n的Webhook节点接收来自网页的用户提问。这个接口可以处理HTTP请求,并将问题传递给后续的处理流程。
- 向量检索相关内容: AI会提供用户提问和系统内置提示词,生成相应的检索查询词,然后使用向量数据库进行相似度搜索。系统会找出与问题最相关的文档片段,作为上下文信息提供给大语言模型。这个过程通过n8n的Vector Store检索节点自动完成,通常会返回3-5个最相关的文档片段。
- 构建提示词并调用 LLM:将检索到的相关内容与用户问题组合成完整的提示词,发送给大语言模型。提示词会要求模型基于提供的上下文回答问题,以确保答案准确且相关。
同样,整个过程也都是n8n封装好相应的节点,我们也只需要在n8n中配置好相应节点和参数即可。下面是具体的实现流程图:
集成到网页
完成问答机器人的搭建后,最后一步就是将它集成到github主页中了,这一步对于开发者来说就更简单了,n8n官方提供了嵌入对话的代码片段,只需要将如下代码嵌入到主页中即可,注意:这里的YOUR_PRODUCTION_WEBHOOK_URL需要替换成你在n8n中创建的Webhook URL,这个URL可以在n8n的Webhook节点中找到。
<link href="https://cdn.jsdelivr.net/npm/@n8n/chat/dist/style.css" rel="stylesheet" />
<script type="module">
import { createChat } from 'https://cdn.jsdelivr.net/npm/@n8n/chat/dist/chat.bundle.es.js';
createChat({
webhookUrl: 'YOUR_PRODUCTION_WEBHOOK_URL'
});
</script>代码会在网页右下角显示一个聊天窗口,用户点击后就可以与机器人对话了。你也可以通过配置选项自定义聊天窗口的样式、位置和行为,使其更好地融入你的网站设计。
总结
通过本文的介绍,我们完成了一个功能完整的GitHub项目问答机器人的搭建。整个过程主要包括三个核心步骤:将书籍内容存储到向量数据库、实现智能问答功能,以及集成到网页中供用户使用。
n8n 的可视化工作流让整个开发过程变得简单直观,即使是没有深厚技术背景的开发者也能快速上手。更重要的是,这套方案具有很好的可扩展性和通用性。你可以将同样的思路应用到任何需要知识问答的场景中,比如产品文档助手、客户服务机器人、学习资料问答系统等。
如果你也有类似的需求,不妨动手尝试一下。在实践过程中如果遇到问题,欢迎在评论区交流讨论。最后,如果你对AI Agent的设计模式感兴趣,欢迎关注我的开源项目《Agentic Design Patterns》,也欢迎star支持。