学过计算机底层原理、了解过很多架构设计或者是做过优化的同学,应该很熟悉局部性原理。即便是非计算机行业的人,在做各种调优、提效时也不得不考虑到局部性,只不过他们不常用局部性一词。如果抽象程度再高一些,甚至可以说地球、生命、万事万物都是局部性的产物,因为这些都是宇宙中熵分布布局、局部的熵低导致的,如果宇宙中处处熵一致,有的只有一篇混沌。
所以什么是 局部性 ?这是一个常用的计算机术语,是指处理器在访问某些数据时短时间内存在重复访问,某些数据或者位置访问的概率极大,大多数时间只访问局部的数据。基于局部性原理,计算机处理器在设计时做了各种优化,比如现代CPU的多级Cache、分支预测…… 有良好局部性的程序比局部性差的程序运行得更快。虽然局部性一词源于计算机设计,但在当今分布式系统、互联网技术里也不乏局部性,比如像用redis这种memcache来减轻后端的压力,CDN做素材分发减少带宽占用率……
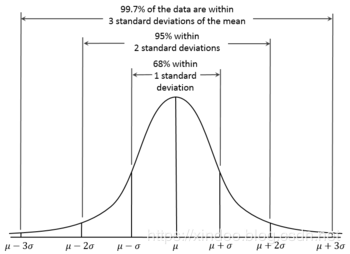
局部性的本质是什么?其实就是概率的不均等,这个宇宙中,很多东西都不是平均分布的,平均分布是概率论中几何分布的一种特殊形式,非常简单,但世界就是没这么简单。我们更长听到的发布叫做高斯发布,同时也被称为正态分布,因为它就是正常状态下的概率发布,起概率图如下,但这个也不是今天要说的。
其实有很多情况,很多事物有很强的头部集中现象,可以用概率论中的泊松分布来刻画,这就是局部性在概率学中的刻画形式。
上面分别是泊松分布的示意图和概率计算公式,$\lambda$ 表示单位时间(或单位面积)内随机事件的平均发生次数,$e$表示自然常数2.71828..,k表示事件发生的次数。要注意在刻画局部性时$\lambda$表示不命中高频数据的频度,$\lambda$越小,头部集中现象越明显。
局部性分类
局部性有两种基本的分类, 时间局部性 和 空间局部性 ,按Wikipedia的资料,可以分为以下五类,其实有些就是时间局部性和空间局部性的特殊情况。
时间局部性(Temporal locality):
如果某个信息这次被访问,那它有可能在不久的未来被多次访问。时间局部性是空间局部性访问地址一样时的一种特殊情况。这种情况下,可以把常用的数据加cache来优化访存。
空间局部性(Spatial locality):
如果某个位置的信息被访问,那和它相邻的信息也很有可能被访问到。 这个也很好理解,我们大部分情况下代码都是顺序执行,数据也是顺序访问的。
内存局部性(Memory locality):
访问内存时,大概率会访问连续的块,而不是单一的内存地址,其实就是空间局部性在内存上的体现。目前计算机设计中,都是以块/页为单位管理调度存储,其实就是在利用空间局部性来优化性能。
分支局部性(Branch locality)
这个又被称为顺序局部性,计算机中大部分指令是顺序执行,顺序执行和非顺序执行的比例大致是5:1,即便有if这种选择分支,其实大多数情况下某个分支都是被大概率选中的,于是就有了CPU的分支预测优化。
等距局部性(Equidistant locality)
等距局部性是指如果某个位置被访问,那和它相邻等距离的连续地址极有可能会被访问到,它位于空间局部性和分支局部性之间。 举个例子,比如多个相同格式的数据数组,你只取其中每个数据的一部分字段,那么他们可能在内存中地址距离是等距的,这个可以通过简单的线性预测就预测是未来访问的位置。
实际应用
计算机领域关于局部性非常多的利用,有很多你每天都会用到,但可能并没有察觉,另外一些可能离你会稍微远一些,接下来我们举几个例子来深入了解下局部性的应用。
计算机存储层级结构
上图来自极客时间徐文浩的《深入浅出计算机组成原理》,我们以目前常见的普通家用电脑为例 ,分别说下上图各级存储的大小和访问速度,数据来源于https://people.eecs.berkeley.edu/~rcs/research/interactive_latency.html。
从最快的L1 Cache到最慢的HDD,其两者的访存时间差距达到了6个数量级,即便是和内存比较,也有几百倍的差距。举个例子,如果CPU在运算是直接从内存中读取指令和数据,执行一条指令0.3ns,然后从内存读下一条指令,等120ns,这样CPU 99%计算时间都会被浪费掉。但就是因为有局部性的存在,每一层都只有少部分数据会被频繁访问,我们可以把这部分数据从底层存储挪到高层存储,可以降低大部分的数据读取时间。
可能有些人好奇,为什么不把L1 缓存做的大点,像内存那么大,直接替代掉内存,不是性能更好吗?虽然是这样,但是L1 Cache单位价格要比内存单位的价格贵好多(大概差200倍),有兴趣可以了解下DRAM和SRAM。
我们可以通过编写高速缓存友好的代码逻辑来提升我们的代码性能,有两个基本方法 。
1. 让最常见的情况运行的快,程序大部分的运行实际都花在少了核心函数上,而这些函数把大部分时间都花在少量循环上,把注意力放在这些代码上。
2. 让每个循环内缓存不命中率最小。比如尽量不要列遍历二维数组。
MemCache
MemCache在大型网站架构中经常看到。DB一般公司都会用mysql,即便是做了分库分表,数据数据库单机的压力还是非常大的,这时候因为局部性的存在,可能很多数据会被频繁访问,这些数据就可以被cache到像redis这种memcache中,当redis查不到数据,再去查db,并写入redis。
因为redis的水平扩展能力和简单查询能力要比mysql强多了,查起来也快。所以这种架构设计有几个好处:
1. 加快了数据查询的平均速度。
2. 大幅度减少DB的压力。
CDN
CDN的全称是Content Delivery Network,即内容分发网络(图片来自百度百科) 。CDN常用于大的素材下发,比如图片和视频,你在淘宝上打开一个图片,这个图片其实会就近从CDN机房拉去数据,而不是到阿里的机房拉数据,可以减少阿里机房的出口带宽占用,也可以减少用户加载素材的等待时间。
CDN在互联网中被大规模使用,像视频、直播网站,电商网站,甚至是12306都在使用,这种设计对公司可以节省带宽成本,对用户可以减少素材加载时间,提升用户体验。看到这,有没有发现,CDN的逻辑和Memcache的使用很类似,你可以直接当他是一个互联网版的cache优化。
Java JIT
JIT全称是Just-in-time Compiler,中文名为即时编译器,是一种Java运行时的优化。Java的运行方式和C++不太一样,因为为了实现write once, run anywhere的跨平台需求,Java实现了一套字节码机制,所有的平台都可以执行同样的字节码,执行时有该平台的JVM将字节码实时翻译成该平台的机器码再执行。问题在于字节码每次执行都要翻译一次,会很耗时。
图片来自郑雨迪Introduction to Graal ,Java 7引入了tiered compilation的概念,综合了C1的高启动性能及C2的高峰值性能。这两个JIT compiler以及interpreter将HotSpot的执行方式划分为五个级别:
- level 0:interpreter解释执行
- level 1:C1编译,无profiling
- level 2:C1编译,仅方法及循环back-edge执行次数的profiling
- level 3:C1编译,除level 2中的profiling外还包括branch(针对分支跳转字节码)及receiver type(针对成员方法调用或类检测,如checkcast,instnaceof,aastore字节码)的profiling
- level 4:C2编译
通常情况下,一个方法先被解释执行(level 0),然后被C1编译(level 3),再然后被得到profile数据的C2编译(level 4)。如果编译对象非常简单,虚拟机认为通过C1编译或通过C2编译并无区别,便会直接由C1编译且不插入profiling代码(level 1)。在C1忙碌的情况下,interpreter会触发profiling,而后方法会直接被C2编译;在C2忙碌的情况下,方法则会先由C1编译并保持较少的profiling(level 2),以获取较高的执行效率(与3级相比高30%)。
这里将少部分字节码实时编译成机器码的方式,可以提升java的运行效率。可能有人会问,为什么不预先将所有的字节码编译成机器码,执行的时候不是更快更省事吗?首先机器码是和平台强相关的,linux和unix就可能有很大的不同,何况是windows,预编译会让java失去夸平台这种优势。 其次,即时编译可以让jvm拿到更多的运行时数据,根据这些数据可以对字节码做更深层次的优化,这些是C++这种预编译语言做不到的,所以有时候你写出的java代码执行效率会比C++的高。
CopyOnWrite
CopyOnWrite写时复制,最早应该是源自linux系统,linux中在调用fork() 生成子进程时,子进程应该拥有和父进程一样的指令和数据,可能子进程会修改一些数据,为了避免污染父进程的数据,所以要给子进程单独拷贝一份。出于效率考虑,fork时并不会直接复制,而是等到子进程的各段数据需要写入才会复制一份给子进程,故此得名 写时复制 。
在计算机的世界里,读写的分布也是有很大的局部性的,大多数情况下读远大于写, 写时复制 的方式,可以减少大量不必要的复制,提升性能。 另外这种方式也不仅仅是用在linux内核中,java的concurrent包中也提供了CopyOnWriteArrayList CopyOnWriteArraySet。像Spark中的RDD也是用CopyOnWrite来减少不必要的RDD生成。
处理
上面列举了那么多局部性的应用,其实还有很多很多,我只是列举出了几个我所熟知的应用,虽然上面这些例子,我们都利用局部性得到了能效、成本上的提升。但有些时候它也会给我们带来一些不好的体验,更多的时候它其实就是一把双刃剑,我们如何识别局部性,利用它好的一面,避免它坏的一面?
识别
文章开头也说过,局部性其实就是一种概率的不均等性,所以只要概率不均等就一定存在局部性,因为很多时候这种概率不均太明显了,非常好识别出来,然后我们对大头做相应的优化就行了。但可能有些时候这种概率不均需要做很详细的计算才能发现,最后还得核对成本才能考虑是否值得去做,这种需要具体问题具体分析了。
如何识别局部性,很简单,看概率分布曲线,只要不是一条水平的直线,就一定存在局部性。
利用
发现局部性之后对我们而言是如何利用好这些局部性,用得好提升性能、节约资源,用不好局部性就会变成阻碍。而且不光是在计算机领域,局部性在非计算机领域也可以利用。
性能优化
上面列举到的很多应用其实就是通过局部性做一些优化,虽然这些都是别人已经做好的,但是我们也可以参考其设计思路。
恰巧最近我也在做我们一个java服务的性能优化,利用jstack、jmap这些java自带的分析工具,找出其中最吃cpu的线程,找出最占内存的对象。我发现有个redis数据查询有问题,因为每次需要将一个大字符串解析很多个键值对,中间会产生上千个临时字符串,还需要将字符串parse成long和double。redis数据太多,不可能完全放的内存里,但是这里的key有明显的局部性,大量的查询只会集中在头部的一些key上,我用一个LRU Cache缓存头部数据的解析结果,就可以减少大量的查redis+解析字符串的过程了。
另外也发现有个代码逻辑,每次请求会被重复执行几千次,耗费大量cpu,这种热点代码,简单几行改动减少了不必要的调用,最终减少了近50%的CPU使用。
非计算机领域
《高能人士的七个习惯》里提到了一种工作方式,将任务划分为重要紧急、不重要但紧急、重要但不紧急、不重要不紧急四种,这种划分方式其实就是按单位时间的重要度排序的,按单位时间的重要度越高收益越大。《The Effective Engineer》里直接用leverage(杠杆率)来衡量每个任务的重要性。这两种方法差不多是类似的,都是优先做高收益率的事情,可以明显提升你的工作效率。
这就是工作中收益率的局部性导致的,只要少数事情有比较大的收益,才值得去做。还有一个很著名的法则82法则,在很多行业、很多领域都可以套用,80%的xxx来源于20%的xxx ,80%的工作收益来源于20%的工作任务,局部性给我们的启示“永远关注最重要的20%” 。
避免
上面我们一直在讲如何通过局部性来提升性能,但有时候我们需要避免局部性的产生。 比如在大数据运算时,时常会遇到数据倾斜、数据热点的问题,这就是数据分布的局部性导致的,数据倾斜往往会导致我们的数据计算任务耗时非常长,数据热点会导致某些单节点成为整个集群的性能瓶颈,但大部分节点却很闲,这些都是我们需要极力避免的。
一般我们解决热点和数据切斜的方式都是提供过重新hash打乱整个数据让数据达到均匀分布,当然有些业务逻辑可能不会让你随意打乱数据,这时候就得具体问题具体分析了。感觉在大数据领域,局部性极力避免,当然如果没法避免你就得通过其他方式来解决了,比如HDFS中小文件单节点读的热点,可以通过减少加副本缓解。其本质上没有避免局部性,只增加资源缓解热点了,据说微博为应对明星出轨Redis集群也是采取这种加资源的方式。
参考资料
- 维基百科局部性原理
- 《计算机组成与设计》 David A.Patterson / John L.Hennessy
- 《深入浅出计算机组成原理》 极客时间 徐文浩
- 《深入理解计算机系统》 Randal E.Bryant / David O'Hallaron 龚奕利 / 雷迎春(译)
- Interactive latencies
- Introduction to Graal 郑雨迪