智能行为通常不仅仅涉及对即时输入做出反应。它需要远见、将复杂任务分解为更小的可管理步骤,以及制定实现期望结果的策略。这就是规划模式发挥作用的地方。规划的核心是 Agent 或 Agent 系统制定一系列行动以从初始状态向目标状态移动的能力。
规划模式概述
在 AI 的背景下,将规划 Agent 视为您委托复杂目标的专家是有帮助的。当您要求它"组织团队外出活动"时,您定义的是"什么"——目标及其约束——而不是"如何"。Agent 的核心任务是自主规划实现该目标的路线。它必须首先理解初始状态(例如,预算、参与者人数、期望日期)和目标状态(成功预订的外出活动),然后发现连接它们的最佳行动序列。计划并不是预先知道的;它是响应请求而创建的。
这个过程的标志是适应性。初始计划仅仅是一个起点,而不是僵化的脚本。Agent 的真正力量在于其整合新信息并引导项目绕过障碍的能力。例如,如果首选场地变得不可用或选择的餐饮服务商已完全预订,一个有能力的 Agent 不会简单地失败。它会适应:记录新的约束,重新评估选项,并制定新计划,也许通过建议替代场地或日期。
然而,认识到灵活性和可预测性之间的权衡至关重要。动态规划是一个特定的工具,而不是通用解决方案。当问题的解决方案已经被充分理解且可重复时,将 Agent 限制为预定的固定工作流更有效。这种方法限制 Agent 的自主性以减少不确定性和不可预测行为的风险,保证可靠和一致的结果。因此,使用规划 Agent 与简单任务执行 Agent 的决定取决于一个问题:是否需要发现"如何",还是已经知道?
实际应用与用例
规划模式是自主系统中的核心计算过程,使 Agent 能够综合一系列行动以实现指定目标,特别是在动态或复杂环境中。这个过程将高级目标转换为由离散可执行步骤组成的结构化计划。
在过程任务自动化等领域,规划用于编排复杂的工作流。例如,像新员工入职这样的业务流程可以分解为定向的子任务序列,例如创建系统帐户、分配培训模块和与不同部门协调。Agent 生成一个计划以逻辑顺序执行这些步骤,调用必要的工具或与各种系统交互以管理依赖关系。
在机器人和自主导航中,规划对于状态空间遍历是基础性的。一个系统,无论是物理机器人还是虚拟实体,都必须生成路径或行动序列以从初始状态转换到目标状态。这涉及优化时间或能源消耗等指标,同时遵守环境约束,如避开障碍物或遵守交通规则。
此模式对于结构化信息综合也至关重要。当被要求生成像研究报告这样的复杂输出时,Agent 可以制定一个包括信息收集、数据总结、内容结构化和迭代完善的不同阶段的计划。同样,在涉及多步问题解决的客户支持场景中,Agent 可以创建并遵循诊断、解决方案实施和升级的系统计划。
从本质上讲,规划模式允许 Agent 从简单的反应性行动转向目标导向的行为。它提供了解决需要一系列相互依赖操作的问题所必需的逻辑框架。
实操代码(Crew AI)
以下部分将演示使用 Crew AI 框架实现规划模式。此模式涉及一个 Agent,它首先制定多步计划以解决复杂查询,然后顺序执行该计划。
import os
from dotenv import load_dotenv
from crewai import Agent, Task, Crew, Process
from langchain_openai import ChatOpenAI
## 从 .env 文件加载环境变量以确保安全
load_dotenv()
## 1. 为清晰起见,明确定义语言模型
llm = ChatOpenAI(model="gpt-4-turbo")
## 2. 定义一个清晰且专注的 Agent
planner_writer_agent = Agent(
role='文章规划者和撰写者',
goal='规划然后撰写关于指定主题的简洁、引人入胜的摘要。',
backstory=(
'你是一位专业的技术作家和内容策略师。'
'你的优势在于在写作之前创建清晰、可操作的计划,'
'确保最终摘要既信息丰富又易于理解。'
),
verbose=True,
allow_delegation=False,
llm=llm # 将特定 LLM 分配给 Agent
)
## 3. 定义具有更结构化和具体的预期输出的任务
topic = "强化学习在 AI 中的重要性"
high_level_task = Task(
description=(
f"1. 为主题'{topic}'的摘要创建要点计划。\n"
f"2. 根据您的计划撰写摘要,保持在 200 字左右。"
),
expected_output=(
"包含两个不同部分的最终报告:\n\n"
"### 计划\n"
"- 概述摘要要点的项目符号列表。\n\n"
"### 摘要\n"
"- 主题的简洁且结构良好的摘要。"
),
agent=planner_writer_agent,
)
## 使用清晰的流程创建团队
crew = Crew(
agents=[planner_writer_agent],
tasks=[high_level_task],
process=Process.sequential,
)
## 执行任务
print("## 运行规划和写作任务 ##")
result = crew.kickoff()
print("\n\n---\n## 任务结果 ##\n---")
print(result)
此代码使用 CrewAI 库创建一个 AI Agent,该 Agent 规划并撰写关于给定主题的摘要。它首先导入必要的库,包括 CrewAI 和 langchainopenai,并从 .env 文件加载环境变量。明确定义了一个 ChatOpenAI 语言模型供 Agent 使用。创建了一个名为 plannerwriter_agent 的 Agent,具有特定的角色和目标:规划然后撰写简洁的摘要。Agent 的背景故事强调其在规划和技术写作方面的专业知识。定义了一个任务,明确描述首先创建计划,然后撰写关于"强化学习在 AI 中的重要性"主题的摘要,并为预期输出指定了特定格式。组建了一个包含 Agent 和任务的团队,设置为顺序处理它们。最后,调用 crew.kickoff() 方法执行定义的任务并打印结果。
Google DeepResearch
Google Gemini DeepResearch(见图 1)是一个基于 Agent 的系统,设计用于自主信息检索和综合。它通过多步 Agent 管道运行,动态和迭代地查询 Google 搜索以系统地探索复杂主题。该系统设计用于处理大量基于网络的资源,评估收集的数据的相关性和知识差距,并执行后续搜索以解决它们。最终输出将经过审核的信息整合成一个结构化的多页摘要,并附有原始来源的引用。
进一步扩展,该系统的运行不是单个查询-响应事件,而是一个受管理的长时间运行过程。它首先将用户的提示词分解为多点研究计划(见图 1),然后呈现给用户审查和修改。这允许在执行之前协作塑造研究轨迹。一旦计划获得批准,Agent 管道就会启动其迭代搜索和分析循环。这不仅仅是执行一系列预定义的搜索;Agent 根据收集的信息动态制定和完善其查询,主动识别知识差距、确认数据点并解决差异。
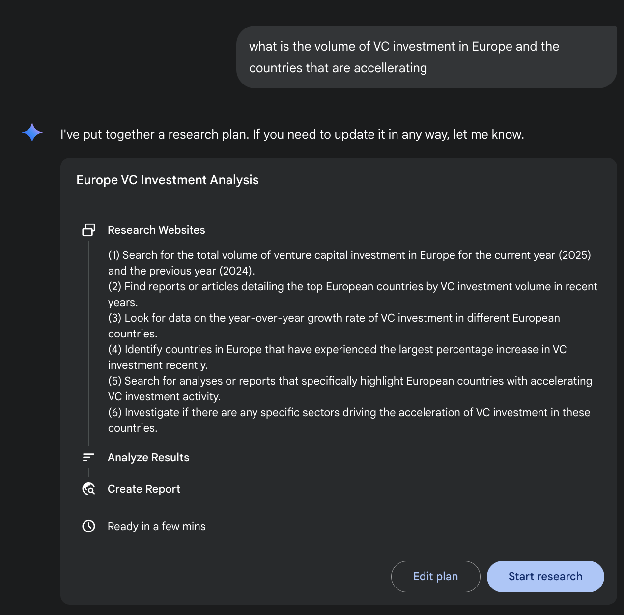
图 1:Google Deep Research Agent 生成使用 Google 搜索作为工具的执行计划。
关键的架构组件是系统异步管理此过程的能力。这种设计确保了调查(可能涉及分析数百个来源)对单点故障具有弹性,并允许用户脱离并在完成时收到通知。系统还可以集成用户提供的文档,将来自私有来源的信息与其基于网络的研究相结合。最终输出不仅仅是发现的串联列表,而是一个结构化的多页报告。在综合阶段,模型对收集的信息进行批判性评估,识别主要主题并将内容组织成具有逻辑部分的连贯叙述。该报告设计为交互式的,通常包括音频概述、图表和指向原始引用来源的链接等功能,允许用户验证和进一步探索。除了综合结果外,模型还明确返回它搜索和咨询的完整来源列表(见图 2)。这些作为引用呈现,提供完全的透明度和对主要信息的直接访问。整个过程将简单的查询转换为全面的、综合的知识体。
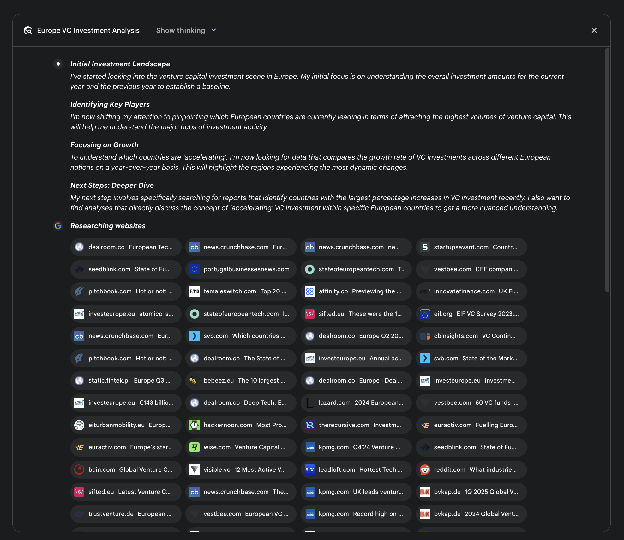
图 2:Deep Research 计划执行的示例,导致使用 Google 搜索作为工具搜索各种网络来源。
通过减轻手动数据获取和综合所需的大量时间和资源投资,Gemini DeepResearch 为信息发现提供了更结构化和详尽的方法。该系统的价值在跨各个领域的复杂、多方面研究任务中尤为明显。
例如,在竞争分析中,可以指示 Agent 系统地收集和整理关于市场趋势、竞争对手产品规格、来自各种在线来源的公众情绪和营销策略的数据。这个自动化过程取代了手动跟踪多个竞争对手的繁重任务,使分析师能够专注于更高层次的战略解释而不是数据收集(见图 3)。

图 3:Google Deep Research Agent 生成的最终输出,代表我们分析使用 Google 搜索作为工具获得的来源。
同样,在学术探索中,该系统作为进行广泛文献综述的强大工具。它可以识别和总结基础论文,追踪概念在众多出版物中的发展,并绘制特定领域内新兴研究前沿的地图,从而加速学术探究的初始和最耗时的阶段。
这种方法的效率源于迭代搜索和过滤周期的自动化,这是手动研究的核心瓶颈。通过系统处理比人类研究人员在可比时间框架内通常可行的更大量和更多样化的信息来源来实现全面性。这种更广泛的分析范围有助于减少选择偏差的潜力,并增加发现不太明显但可能至关重要的信息的可能性,从而导致对主题更稳健和充分支持的理解。
OpenAI Deep Research API
OpenAI Deep Research API 是一个专门设计用于自动化复杂研究任务的工具。它利用一个先进的 Agent 模型,可以独立推理、规划和从现实世界来源综合信息。与简单的问答模型不同,它接受高级查询并自主将其分解为子问题,使用其内置工具执行网络搜索,并提供结构化的、富含引用的最终报告。该 API 提供对整个过程的直接程序化访问,在撰写本文时使用 o3-deep-research-2025-06-26 等模型进行高质量综合,以及更快的 o4-mini-deep-research-2025-06-26 用于延迟敏感的应用程序。
Deep Research API 很有用,因为它自动化了原本需要数小时的手动研究,提供适合为业务战略、投资决策或政策建议提供信息的专业级、数据驱动的报告。其主要好处包括:
- 结构化、引用的输出: 它产生组织良好的报告,带有链接到来源元数据的内联引用,确保声明可验证且有数据支持。
- 透明度: 与 ChatGPT 中的抽象过程不同,API 公开所有中间步骤,包括 Agent 的推理、它执行的特定网络搜索查询以及它运行的任何代码。这允许详细的调试、分析以及更深入地理解最终答案是如何构建的。
- 可扩展性: 它支持模型上下文协议(MCP),使开发人员能够将 Agent 连接到私有知识库和内部数据源,将公共网络研究与专有信息混合。
要使用 API,您向 client.responses.create 端点发送请求,指定模型、输入提示词和 Agent 可以使用的工具。输入通常包括定义 Agent 角色和期望输出格式的 systemmessage,以及 userquery。您还必须包括 websearchpreview 工具,并可以选择添加其他工具,如 code_interpreter 或自定义 MCP 工具(见第 10 章)用于内部数据。
from openai import OpenAI
## 使用您的 API 密钥初始化客户端
client = OpenAI(api_key="YOUR_OPENAI_API_KEY")
## 定义 Agent 的角色和用户的研究问题
system_message = """你是一名准备结构化、数据驱动报告的专业研究员。专注于数据丰富的见解,使用可靠的来源,并包括内联引用。"""
user_query = "研究司美格鲁肽对全球医疗保健系统的经济影响。"
## 创建 Deep Research API 调用
response = client.responses.create(
model="o3-deep-research-2025-06-26",
input=[
{
"role": "developer",
"content": [{"type": "input_text", "text": system_message}]
},
{
"role": "user",
"content": [{"type": "input_text", "text": user_query}]
}
],
reasoning={"summary": "auto"},
tools=[{"type": "web_search_preview"}]
)
## 从响应中访问并打印最终报告
final_report = response.output[-1].content[0].text
print(final_report)
## --- 访问内联引用和元数据 ---
print("--- 引用 ---")
annotations = response.output[-1].content[0].annotations
if not annotations:
print("报告中未找到注释。")
else:
for i, citation in enumerate(annotations):
# 引用所指的文本范围
cited_text = final_report[citation.start_index:citation.end_index]
print(f"引用 {i+1}:")
print(f" 引用文本:{cited_text}")
print(f" 标题:{citation.title}")
print(f" URL:{citation.url}")
print(f" 位置:字符 {citation.start_index}–{citation.end_index}")
print("\n" + "="*50 + "\n")
## --- 检查中间步骤 ---
print("--- 中间步骤 ---")
## 1. 推理步骤:模型生成的内部计划和摘要。
try:
reasoning_step = next(item for item in response.output if item.type == "reasoning")
print("\n[找到推理步骤]")
for summary_part in reasoning_step.summary:
print(f" - {summary_part.text}")
except StopIteration:
print("\n未找到推理步骤。")
## 2. 网络搜索调用:Agent 执行的确切搜索查询。
try:
search_step = next(item for item in response.output if item.type == "web_search_call")
print("\n[找到网络搜索调用]")
print(f" 执行的查询:'{search_step.action['query']}'")
print(f" 状态:{search_step.status}")
except StopIteration:
print("\n未找到网络搜索步骤。")
## 3. 代码执行:Agent 使用代码解释器运行的任何代码。
try:
code_step = next(item for item in response.output if item.type == "code_interpreter_call")
print("\n[找到代码执行步骤]")
print(" 代码输入:")
print(f" ```python\n{code_step.input}\n ```")
print(" 代码输出:")
print(f" {code_step.output}")
except StopIteration:
print("\n未找到代码执行步骤。")
此代码片段利用 OpenAI API 执行"深度研究"任务。它首先使用您的 API 密钥初始化 OpenAI 客户端,这对于身份验证至关重要。然后,它将 AI Agent 的角色定义为专业研究员,并设置用户关于司美格鲁肽经济影响的研究问题。代码构造对 o3-deep-research-2025-06-26 模型的 API 调用,提供定义的系统消息和用户查询作为输入。它还请求推理的自动摘要并启用网络搜索功能。进行 API 调用后,它提取并打印最终生成的报告。
随后,它尝试访问并显示报告注释中的内联引用和元数据,包括引用文本、标题、URL 和报告中的位置。最后,它检查并打印模型采取的中间步骤的详细信息,例如推理步骤、网络搜索调用(包括执行的查询)以及如果使用了代码解释器的任何代码执行步骤。
概览
什么: 复杂问题通常无法通过单个操作解决,需要远见才能实现期望的结果。没有结构化的方法,Agent 系统难以处理涉及多个步骤和依赖关系的多方面请求。这使得将高级目标分解为一系列可管理的更小可执行任务变得困难。因此,系统无法有效地制定策略,在面对复杂目标时导致不完整或不正确的结果。
为什么: 规划模式通过让 Agent 系统首先创建一个连贯的计划来解决目标提供了标准化解决方案。它涉及将高级目标分解为一系列更小的可操作步骤或子目标。这允许系统管理复杂的工作流、编排各种工具并以逻辑顺序处理依赖关系。LLM 特别适合这一点,因为它们可以基于其庞大的训练数据生成合理且有效的计划。这种结构化方法将简单的反应性 Agent 转变为战略执行者,可以主动朝着复杂目标工作,甚至在必要时调整其计划。
经验法则: 当用户的请求太复杂而无法通过单个操作或工具处理时使用此模式。它非常适合自动化多步流程,例如生成详细的研究报告、新员工入职或执行竞争分析。每当任务需要一系列相互依赖的操作以达到最终的综合结果时,应用规划模式。
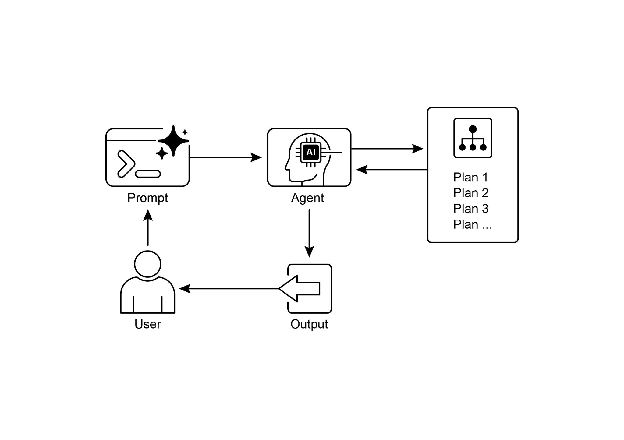
视觉摘要
** **
**
图 4;规划设计模式
关键要点
- 规划使 Agent 能够将复杂目标分解为可操作的顺序步骤。
- 它对于处理多步任务、工作流自动化和导航复杂环境至关重要。
- LLM 可以通过基于任务描述生成逐步方法来执行规划。
- 明确提示或设计任务以要求规划步骤会在 Agent 框架中鼓励这种行为。
- Google Deep Research 是一个代表我们分析使用 Google 搜索作为工具获得的来源的 Agent。它反思、规划并执行。
结论
总之,规划模式是将 Agent 系统从简单的反应性响应者提升为战略性、目标导向的执行者的基础组件。现代大型语言模型为此提供了核心能力,自主地将高级目标分解为连贯的可操作步骤。此模式从简单的顺序任务执行(如 CrewAI Agent 创建并遵循写作计划所演示的)扩展到更复杂和动态的系统。Google DeepResearch Agent 体现了这种高级应用,创建基于持续信息收集而适应和演化的迭代研究计划。最终,规划为复杂问题的人类意图和自动化执行之间提供了必要的桥梁。通过构建问题解决方法,此模式使 Agent 能够管理复杂的工作流并提供全面的综合结果。
参考文献
- Google DeepResearch (Gemini Feature): gemini.google.com
- OpenAI ,Introducing deep research https://openai.com/index/introducing-deep-research/
- Perplexity, Introducing Perplexity Deep Research, https://www.perplexity.ai/hub/blog/introducing-perplexity-deep-research
本文来源于开源项目Agentic Design Patterns中文翻译








I tried a two products from Tillmans Tranquils – relief gummies and in reality liked the complete experience. The gummies be struck by a straighten up grain, slick consistency, and dependable quality. The flavors feel reasonable, and the portioned servings make it amenable to choose what works for you. Their packaging looks premium and the total feels thoughtfully made. A downright brand with products that are enjoyable and reliable.