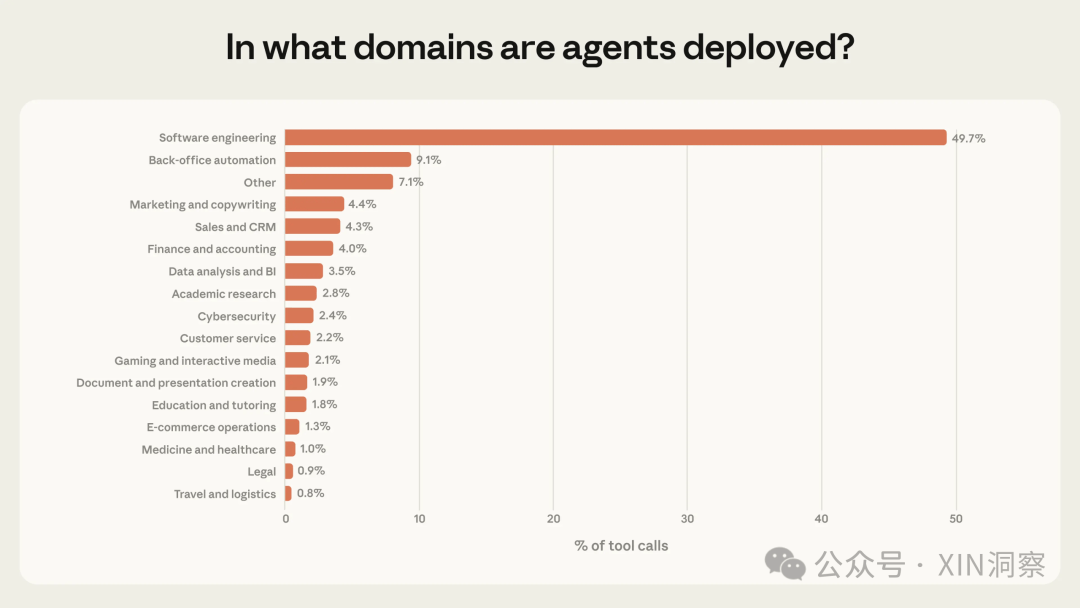
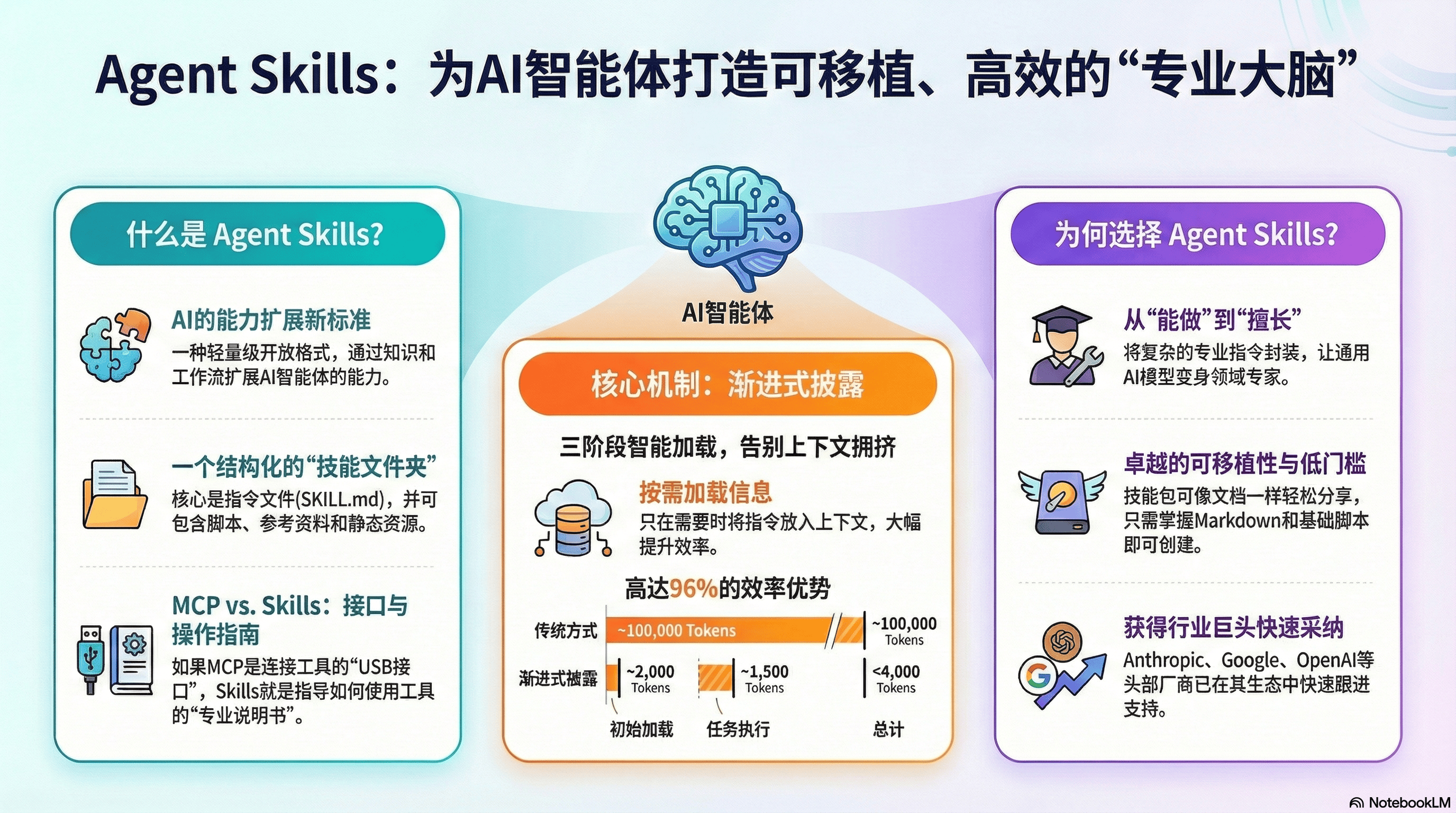
基础概念
提示词(Prompt): 提示词是用户向 AI 模型提供的输入,通常以问题、指令或陈述形式呈现,旨在激发模型生成相应输出。提示词的质量与结构深度影响模型响应效果,使提示工程成为高效运用 AI 的核心技能。
上下文窗口(Context Window): 上下文窗口指 AI 模型单次处理的最大 token 容量,涵盖输入内容与生成输出。此固定尺寸构成关键限制——超出窗口范围的信息将被忽略,而更大窗口则支持更复杂对话交互与文档分析能力。
上下文学习(In-Context Learning): 上下文学习是 AI 通过提示中直接嵌入的示例掌握新任务的能力,无需额外训练过程。此强大特性使单一通用模型可即时适配海量特定任务场景。
零样本、单样本与少样本提示(Zero-Shot, One-Shot, & Few-Shot Prompting): 此类提示技术通过提供零个、单个或少量任务示例引导模型生成响应。增加示例数量通常能提升模型对用户意图的把握精度,增强特定任务表现。
多模态(Multimodality): 多模态指 AI 理解并处理跨数据类型信息(如文本、图像、音频)的能力。该特性支持更丰富类人化交互,例如图像描述或语音问答场景。
事实锚定(Grounding): 事实锚定是将模型输出关联至可验证真实信息源的过程,旨在确保事实准确性并降低幻觉发生。常通过 RAG 等技术实现,提升 AI 系统可信度。
核心 AI 模型架构
Transformer: Transformer 构成多数现代 LLM 的基石神经网络架构。其核心创新自注意力机制能高效处理长文本序列,精准捕捉词汇间复杂关联。
循环神经网络(Recurrent Neural Network, RNN): 循环神经网络是早于 Transformer 的基础架构。RNN 采用序列化信息处理方式,通过循环结构维持对历史输入的"记忆",曾广泛应用于文本与语音处理任务。
专家混合(Mixture of Experts, MoE): 专家混合为高效模型架构,通过"路由"网络动态筛选少量"专家"网络处理特定输入。该设计使模型在保持海量参数规模的同时,有效控制计算开销。
扩散模型(Diffusion Models): 扩散模型是专精高质量图像生成的生成式模型。其工作原理是通过向数据注入随机噪声,继而训练模型精确逆转该过程,从而实现从随机初始状态生成新颖数据。
Mamba: Mamba 是采用选择性状态空间模型(Selective State Space Model, SSM)的新兴 AI 架构,具备超长上下文序列的高效处理能力。其选择性机制可聚焦相关信息同时滤除噪声,被视为 Transformer 的潜在替代方案。
LLM 开发生命周期
强大语言模型的开发遵循明确演进路径。初始阶段为预训练(Pre-training)——通过海量通用互联网文本数据集训练构建大规模基础模型,掌握语言规律、推理能力与世界知识。随后进入微调(Fine-tuning)阶段,通用模型在较小规模任务特定数据集上进一步训练,实现面向特定场景的能力适配。最终阶段为对齐(Alignment),调整专业化模型行为模式,确保输出兼具实用性、安全性且符合人类价值导向。
预训练技术(Pre-training Techniques): 预训练是模型从海量数据中汲取通用知识的奠基阶段。该领域顶尖技术涵盖多样化的学习目标设定。最普遍的是因果语言建模(Causal Language Modeling, CLM),模型通过预测句中下一词汇进行学习。另一主流方法是掩码语言建模(Masked Language Modeling, MLM),模型负责还原文本中被刻意遮蔽的词汇。其他关键方法论包括:去噪目标(Denoising Objectives)——模型学习将受损输入修复至原始状态;对比学习(Contrastive Learning)——模型习得区分相似与相异数据片段的能力;以及下句预测(Next Sentence Prediction, NSP)——模型判断两句间是否存在逻辑连贯性。
微调技术(Fine-tuning Techniques): 微调是使用专业化小规模数据集将通用预训练模型适配至特定任务的过程。最常用方法为监督微调(Supervised Fine-Tuning, SFT),模型在标注准确的输入输出配对示例上进行训练。指令微调(Instruction Tuning)作为流行变体,重点提升模型遵循用户指令的精准度。为提升过程效率,普遍采用参数高效微调(Parameter-Efficient Fine-Tuning, PEFT)方法,其中代表性技术包括 LoRA(低秩适应)——仅更新少量参数,及其内存优化版本 QLoRA。检索增强生成(Retrieval-Augmented Generation, RAG)作为补充技术,通过在微调或推理阶段连接外部知识源增强模型能力。
对齐与安全技术(Alignment & Safety Techniques): 对齐是确保 AI 模型行为契合人类价值观与期望的过程,使其输出兼具帮助性与安全性。最突出的技术是基于人类反馈的强化学习(Reinforcement Learning from Human Feedback, RLHF),通过基于人类偏好训练的"奖励模型"指导 AI 学习过程,常辅以近端策略优化(Proximal Policy Optimization, PPO)等算法保障训练稳定性。近年涌现的简化替代方案包括直接偏好优化(Direct Preference Optimization, DPO)——规避独立奖励模型需求,以及卡尼曼-特沃斯基优化(Kahneman-Tversky Optimization, KTO)——进一步简化数据收集流程。为确保部署安全,护栏(Guardrails)作为终态安全层被广泛应用,实时过滤输出并阻断有害行为。
增强 AI Agent 能力
AI Agent 是能感知环境并采取自主行动以实现目标的智能系统。其效能通过强大的推理框架显著提升。
思维链(Chain of Thought, CoT): 该提示技术引导模型在给出最终答案前逐步展示推理过程。此类"显式思考"机制常在复杂推理任务中产生更精确结果。
思维树(Tree of Thoughts, ToT): 思维树是进阶推理框架,Agent 同步探索多条推理路径(如树枝分叉)。该框架支持 Agent 自评估不同思路质量,择优推进最 promising 路径,极大增强复杂问题解决效能。
ReAct(推理-行动框架,Reason and Act): ReAct 是将推理与工具使用融合于循环流程的 Agent 框架。Agent 先进行"思考"确定行动方向,随后通过工具执行"行动",并依据执行结果"观察"调整后续思考,该机制在复杂任务解决中表现卓越。
规划(Planning): 指 Agent 将高层目标分解为系列可管理子任务的能力。Agent 据此制定执行计划并按序推进步骤,从而胜任复杂的多阶段任务。
深度研究(Deep Research): 深度研究指 Agent 通过迭代式信息检索、发现整合与新问题识别,实现对主题的自主深入探索能力。这使得 Agent 能构建远超单次查询范围的 comprehensive 主题认知。
评审模型(Critique Model): 评审模型是经专门训练的 AI 模型,用于审查、评估并对其他 AI 模型输出提供反馈。其扮演自动化评审者角色,协助识别错误、优化推理流程并确保最终输出符合预期质量标准。
本文来源于开源项目Agentic Design Patterns中文翻译