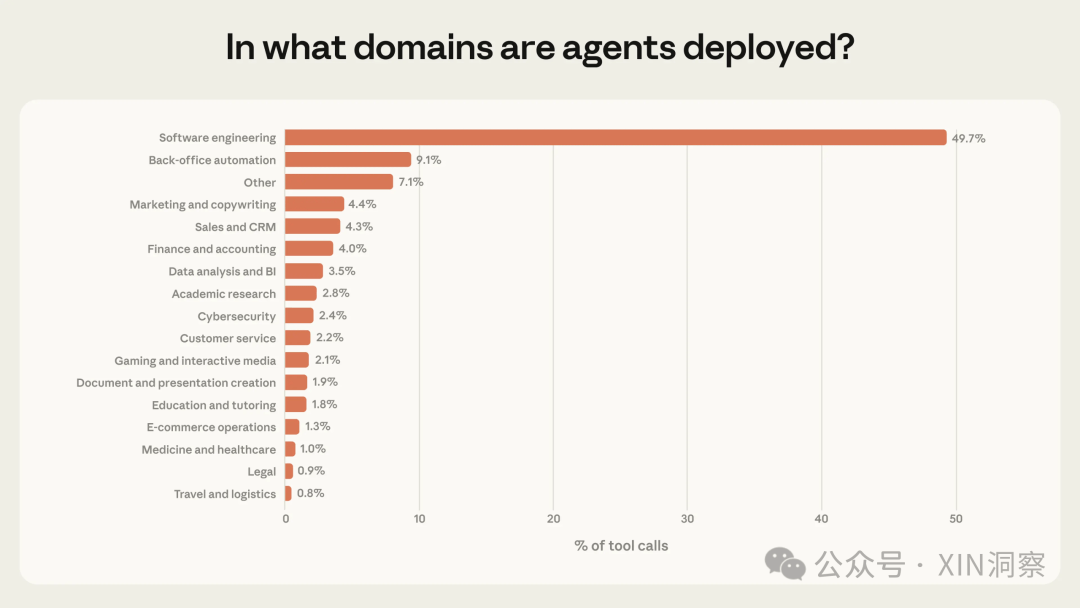
本文首发于公众号:XIN洞察——资深博主,做过运维、写过代码、现任产品经理,从命令行终端敲到产品设计稿,跨视角硬核解码新时代的XIN洞察。欢迎关注,先一步获取我的最新文章。
一种新型的「凡尔赛」正在 AI 圈流行
最近半年,AI 编程圈悄悄诞生了一种新型“凡尔赛”——比谁更能烧 Token。
刷一圈 X、小红书、知乎和各路技术博客,你会看到这样一幅奇景:
- OpenClaw(“龙虾”)作者 Peter 自爆,30 天烧掉 6030 亿 token,发起 760 万次请求,总开销超过 130 万美元;
- 中国“Claude Code 榜一大哥” 刘小排——X 上自认 Anthropic 公告里“在 200 美元套餐里消耗了 5 万美元模型用量”的那位用户,过去一个月烧掉 77 亿 token,价值 超 5 万美元,逼得 Anthropic 连夜推出每周速率限制;
- Factory 开发者关系主管 Ben Tossell 在一篇浏览量超过 360 万的 X 长文里晒出战绩:4 个月烧掉 30 亿 token,被网友冠名“30 亿 token 调度者”;
- 隔壁的 NVIDIA 直接把 Cursor 部署到了所有 4 万名工程师身上,黄仁勋亲口说“100% 的工程师都在用 AI 编程”,代码产出涨了 3 倍——光这一条就够全行业打工人羡慕一年;
- 迪士尼内部上线的 “AI Adoption Dashboard” 直接公开员工 Token 排行榜,某位“榜一大哥” 9 个工作日调用 Claude 46 万次——平均每 1.7 秒一次,堪称肉身定时器。
整个行业内,一把梭哈疯狂烧 Token,有种 “一天不烧个几亿 Token,都不好意思说自己是 AI 圈的人” 的感觉。
这话半是调侃,半是真相。它精准地捕捉到了当下 AI 行业的一种集体性焦虑——烧 Token 的多少,正在被默认为衡量“AI 用得有多深”的代理指标。
烧得多,意味着你在认真用 AI;烧得少,则有种“是不是没跟上时代”的隐忧。于是越来越多的人开始把 Token 消耗量晒出来,作为一种新型的“身份徽章”——就像十年前晒 GitHub 提交、五年前晒微信运动步数一样。
只不过这次,徽章背后烧的是真金白银。
Token 到底有多贵?
要理解“烧 Token 竞赛”的荒诞,先得知道 Token 到底有多贵。
不同模型、不同档位的 Token 价格差异很大——从最便宜的开源小模型到最贵的旗舰推理模型,同样 1 亿 Token,成本可以相差几十倍。
这里可以用 Cursor 披露的一组数据做一个更贴近 AI 编程场景的估算:在典型 Agent 调用里,输入 Token 和输出 Token 的比例大约是 13:1,同时 Prompt 缓存命中率可以做到 90% 左右(实测中不同模型差异较大:DeepSeek 最高能到 95%,而 Claude、GLM 等其他模型在 cc-switch 日常统计中多在 80%+,这里以 90% 作为参考值计算)。
按这个结构估算,并按当前汇率粗略折算成人民币,主流模型的 1 亿 Token 成本大致是:
| 模型 | 1 亿总 Token 成本 |
|---|---|
| DeepSeek V4 Flash | 约 25 元 |
| DeepSeek V4 Pro | 约 73 元 |
| GLM 5.2 | 约 310 元 |
| Claude Sonnet 4.6 | 约 1011 元 |
| Claude Opus 4.8 | 约 2192 元 |
这个差距非常夸张:在 Cursor 这种“高输入、低输出、高缓存命中”的调用结构下,DeepSeek v4 Pro 的名义 API 成本大约只有 Claude Opus 的 1/28 到 1/31。当然,价格不是唯一变量,模型能力、稳定性、工具调用质量、代码理解深度都要算进去;但单看 Token 账单,差距已经足够影响产品和公司层面的模型选型。
听起来不算很贵,对吧?如果用便宜模型,1 亿 Token 的成本可能还不如请人吃一顿火锅;但如果用旗舰模型,1 亿 Token 就已经是一笔需要认真管理的成本。
更重要的是——1 亿 Token 真的不算多。
在 AI 编程的场景里,一次 Agent 任务从读代码、思考、写代码、运行测试到自我修复,几万到几十万 Token 是常态;一个稍微复杂的项目跑一整天,几亿 Token 转眼就没了。所以当你听到“月烧 77 亿”的时候——这其实就是一个 AI 编程深度玩家的正常用量。
我们把数字摊开做个简单换算:
按前文口径折算:Claude Opus ≈ 1700 元 / 1 亿 token(高端旗舰)、DeepSeek v4 Pro ≈ 59 元 / 1 亿 token(国产低价),两者相差近 30 倍。下表把开头提到的几位“凡尔赛主角”放进同一把尺子里看:
| 用量级别 | 大致月度 Token | 全用 DeepSeek v4 Pro | 全用 Claude Opus |
|---|---|---|---|
| 普通开发者偶尔用 | 千万级(<1 亿) | 几元 — 几十元 | 几百 — 1700 元 |
| Ben Tossell“30 亿 token 调度者”(4 个月 30 亿) | 月均 ~7.5 亿 | 约 440 元 | 约 1.3 万元 |
| 刘小排级重度用户(月烧 77 亿) | 几十亿级 | 约 4500 元 | 约 13 万元(实际包月折抵后超 5 万美元 ≈ 36 万元) |
| 龙虾 Peter“月烧 6030 亿” | 6000 亿+ | 约 35 万元 | 约 1000 万元(实际账单 130 万美元 ≈ 936 万元) |
看到这里,结论已经很清楚了:
当一个人的 AI 账单超过他的工资时,他就成了 AI 的“重氪用户”;当一个人的 AI 账单超过整个团队的工资时,公司就该开始算账了。
“敞开了烧”的 AI,成本早已远远超过雇一个高级工程师。一个月烧 130 万美元的 OpenClaw 作者,相当于雇佣几十个硅谷高级工程师全职给他打工——只不过他选择把这笔钱全交给了模型厂商。
这才是“烧 Token 凡尔赛”最荒诞的地方:炫耀的不是产出,是消耗。
大家为什么越烧越多?
要回答这个问题,得先理解一个变化:过去一年,AI 的使用方式发生了从“对话”到“自主执行”的范式跃迁。
早期的 AI 用法,绝大多数是对话式——你问一句,它答一句。一次对话上下文也就几千、几万 Token,烧得再多也有限。这是为什么 2024 年之前几乎没人讨论“Token 烧得多”这件事。
但 Claude Code、Codex、OpenClaw、Cursor Agent…… 这一波 Agent 化产品起来之后,画风彻底变了:
- AI 不再是“回答问题”,而是“接管任务”——读完整个仓库、规划步骤、写代码、跑测试、自我纠错;
- 一次任务的上下文可以轻松到几十万 Token;
- 而且 AI 可以 7×24 跑——你睡觉它在跑,你吃饭它在跑,你开会它还在跑;
- 多 Agent 并行、子任务 fan-out、长时间研究型工作流……这些新范式让 Token 消耗呈指数级增长。
更关键的是,模型厂商在这一波浪潮里给出了“包月吃到饱”的定价——Claude Max、Cursor Ultra、各种企业版套餐,让重度用户在一个固定预算下“敞开了用”。
而站在另一端的“金主”们,也在用一种近乎 PUA 的方式鼓励员工烧。黄仁勋在 GTC 2026 的炉边谈话里有一句很出圈的话:
“如果一个年薪 50 万美元的工程师,用不了 25 万美元的 Token,我会很焦虑。”
把“Token 消耗量”明确钉在了“工程师产出/价值”的对立面——烧得少不是省钱,是失职。 这种来自最高层的叙事,再叠加包月套餐和 Agent 的自动消耗,就构成了完美的“烧 Token 三件套”:老板鼓励烧、套餐允许烧、Agent 自动烧。
于是烧 Token 这件事,从“主动消费”变成了“被动产生”:你只需要把任务丢给 Agent,它自己就会去烧。烧完之后你看一眼报表,惊叹一句“我居然烧了这么多”,然后截个图发出来——一个新的凡尔赛诞生了。
但有些公司,已经在踩刹车了
但故事正在悄悄反转。
就在所有人都在比谁烧得多的时候,已经有一些公司开始默默地给员工的 AI 预算设上限了。
这不是新闻的头条,因为它不性感——没有“月烧百万美金”那么吸睛。但它是更真实、更值得关注的信号。当某些团队开始计算每个工程师的“人均 AI ROI”,开始把 AI 工具的使用纳入成本中心管理,开始在月度复盘里要求工程师说明 Token 花在了哪、产出了什么时,“烧 Token 凡尔赛”的派对就快开不下去了。
而且这次“刹车”踩得相当整齐。2026 年年中,全球头部科技企业几乎同步从“管够”切换到了“算账”模式:
- Meta:有员工自己撸了个 “Claudeonomics” 内部工具,统计了 8.5 万员工的 Token 消耗——30 天 60 万亿 token、约 90 亿美元;榜首单人 30 天就烧掉 2810 亿 token(具体折算金额未公开,业内估算在数十万美元级别),而扎克伯格本人和 CTO Bosworth 都没能挤进 Top 250(后因数据外泄,Meta 已关闭该看板)。
- 腾讯:3 月还在推行“每人年均 22 万元 Token 资源”的激励政策(每月含 700 美元 Cursor + 700 美元 Claude + 1000 美元 CodeBuddy),6 月直接砍至月度硬上限——核心 AI 团队(混元、优图)约 5250—7000 元,降幅约 50—60%;边缘岗位(如腾讯娱乐外包)仅 1000 元,降幅超 90%。
- Uber:把 Claude Code 推给约 5000 名工程师后,人均月烧 500—2000 美元,4 个月就把 2026 年 AI 预算全部烧光(参考量级:Uber 2025 年 R&D 总支出 34 亿美元,YoY +9%;AI 预算具体规模未公开)。
- 微软:GitHub Copilot 自 2026 年 6 月 1 日起切换为基于 Token 的按量计费——月费保留(Pro 10 美元、Pro+ 39 美元、Max 100 美元),但额度变成 GitHub AI Credits,用完按 Token 单价续扣,过去“高级请求次数”机制取消。
- 字节:自研模型工作场景不限量,但外部模型走“先垫付、后报销”——产品/技术序列年上限 1000 美元、其他序列 300 美元,且采用 Copay 模式(公司 50%/个人 50%)。
- 阿里:3 月起向员工发放 Token 额度,免费提供悟空、Qoder 等内部工具,购买百炼 Coding Plan 或外部 AI 工具可申请报销;具体月度上限按部门有所不同,整体策略相对克制。
从“22 万年包”到“月 1000 块”、从“AI 预算管一年”到“4 个月烧光”,这种落差不是某家公司的内部决策,而是整个行业对 AI 成本认知的集体校准。
这背后是一个被互联网集体忽视的根本性问题:
我们在互联网上听到的,全是 AI 的“百万级投入”——某某公司又上了多少卡、某某团队又烧了多少 Token、某某独立开发者又花了多少美金。但几乎从来没听说过——某个产品因为用了 AI 拿到了“百万级的产出”。
烧钱的故事满天飞,赚钱的故事却出奇地安静。
这并不是说 AI 没有创造价值——它显然创造了。但创造的价值和投入的成本之间,到底是不是一笔合算的账?这个问题,绝大多数公司还没有答案。
更让人警觉的是,当“烧 Token 的多少”被默认为“AI 用得多深”的代理指标时,整个行业的注意力就开始从“创造价值”漂移到“消耗资源”。员工会下意识地多烧、CEO 会自豪地晒出账单、模型厂商乐于鼓吹这种叙事——所有人都在比谁烧得更多,但没人问:烧完之后,到底产出了什么?
这跟过去互联网时代“烧补贴抢用户”的剧本何其相似。区别只在于,那时候烧的是用户补贴,至少能换来 DAU;而现在烧的是 GPU 算力,换来的可能只是一份月底的账单和一张推特截图。
烧 Token 的尽头是什么?
如果我们承认 Token 不是免费的、AI 不是慈善业、公司账上的钱不是从天上掉下来的——那么 “烧 Token 凡尔赛”就一定会终结 。问题只在于早晚、以及怎么终结。
我个人的判断是,未来 1-2 年内,Token 消耗会经历一次明显的从“展示导向”到“价值导向”的回归。具体会沿着三条路径推进:
第一,公司层面的 AI 预算精细化。 那些早期“敞开了让员工用”的公司,会陆续引入预算上限、按部门/项目分配 Token 配额、要求月度 ROI 复盘。CFO 们会开始问:这 100 万的 AI 账单,对应的是哪些产品功能?哪些线上收入?哪些效率提升?没有清晰答案的部门,预算会被砍。
第二,个人层面的“高效烧 Token”成为新技能。 跟过去“会写 Prompt”成为热门技能一样,未来“用更少的 Token 拿到更好的结果”会成为新的差异化能力。这意味着一整套 “省 Token”的工程实践 会被广泛重视:怎么拆分任务能让上下文最短?什么场景用 Opus 什么场景用 Sonnet/Haiku?怎么把 Prompt 缓存命中率从 60% 拉到 90%+?哪些工作流可以用本地模型替代云服务?回到我们一开始引用的 Cursor 数据——输入与输出 13:1、缓存命中率可达 90%——意味着真正的大头不是模型“写了多少”,而是它为了完成任务反复读取、理解、检索、压缩了多少上下文;只要工作流设计得足够稳定、上下文组织得足够工程化,很多看似不可避免的 Token 消耗其实是可以被系统性摊薄的。
第三,模型厂商也会被倒逼优化定价和效率。 当客户开始算账,“包月吃到饱”的粗放定价就维持不下去了。我们会看到更精细的分层(按 Agent 任务类型、按模型档位、按缓存命中率)、更激进的成本压缩(蒸馏、MoE、推理优化),以及更明确的“价值定价”模型——为客户的产出而不是消耗付费。
到那时,再回头看 2026 这场“烧 Token 凡尔赛”,会有一种很怀念的复杂感——就像现在回看 2014 年那波 O2O 烧钱补贴大战一样:当时所有人都觉得是常态,事后回看其实是个非常短暂的窗口期。
那些在“烧得多就是用得深”的叙事里沉迷得最深的人,可能也会被这次价值回归冲击得最严重。因为他们烧了那么多 Token,却没有沉淀出对应的“产出能力”——他们炫耀的是消耗量,不是创造力。
而被预算逼着精打细算的人,反而会比“敞开了烧”的人更早一步迈过这道价值关——这大概是这场凡尔赛大戏里,最不起眼也最有意思的一个伏笔。